
wink-bm25-text-search
v3.1.2
Published
Configurable BM25 Text Search Engine with simple semantic search support



Readme
wink-bm25-text-search
Fast Full Text Search based on BM25


The wink-bm25-text-search, based on BM25 — a probabilistic relevance algorithm for document retrieval, is a full text search package to develop apps in either Node.js or browser environments. It builds an in-memory search index from input JSON documents, which is optimized for size and speed.
Explore wink BM25 text search example to dig deeper:
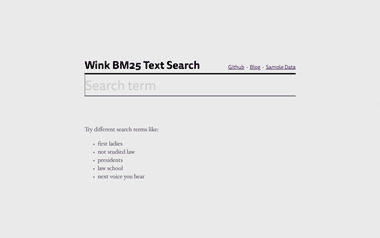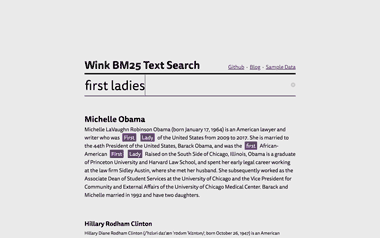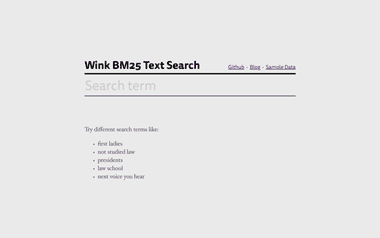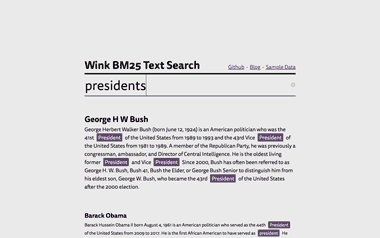
Its code is available in showcase-bm25-text-search repo along with a detailed blog post.
It is easy to add semantic flavor to the search by:
Assigning different numerical weights to the fields. A negative field weight will pull down the document's score whenever a match with that field occurs.
Using rich text processing features of wink-nlp such as negation detection, stemming, lemmatization, stop word detection and named entity detection to perform intelligent searches.
Defining different text preparation tasks separately for the fields and query text.
Installation
Use npm to install:
npm install wink-bm25-text-search --saveExample 
// Load wink-bm25-text-search
var bm25 = require( 'wink-bm25-text-search' );
// Create search engine's instance
var engine = bm25();
// Load sample data (load any other JSON data instead of sample)
var docs = require( 'wink-bm25-text-search/sample-data/demo-data-for-wink-bm25.json' );
// Load wink nlp and its model
const winkNLP = require( 'wink-nlp' );
// Use web model
const model = require( 'wink-eng-lite-web-model' );
const nlp = winkNLP( model );
const its = nlp.its;
const prepTask = function ( text ) {
const tokens = [];
nlp.readDoc(text)
.tokens()
// Use only words ignoring punctuations etc and from them remove stop words
.filter( (t) => ( t.out(its.type) === 'word' && !t.out(its.stopWordFlag) ) )
// Handle negation and extract stem of the word
.each( (t) => tokens.push( (t.out(its.negationFlag)) ? '!' + t.out(its.stem) : t.out(its.stem) ) );
return tokens;
};
// Contains search query.
var query;
// Step I: Define config
// Only field weights are required in this example.
engine.defineConfig( { fldWeights: { title: 1, body: 2 } } );
// Step II: Define PrepTasks pipe.
// Set up 'default' preparatory tasks i.e. for everything else
engine.definePrepTasks( [ prepTask ] );
// Step III: Add Docs
// Add documents now...
docs.forEach( function ( doc, i ) {
// Note, 'i' becomes the unique id for 'doc'
engine.addDoc( doc, i );
} );
// Step IV: Consolidate
// Consolidate before searching
engine.consolidate();
// All set, start searching!
query = 'not studied law';
// `results` is an array of [ doc-id, score ], sorted by score
var results = engine.search( query );
// Print number of results.
console.log( '%d entries found.', results.length );
// -> 1 entries found.
// results[ 0 ][ 0 ] i.e. the top result is:
console.log( docs[ results[ 0 ][ 0 ] ].body );
// -> George Walker Bush (born July 6, 1946) is an...
// -> ... He never studied Law...
// Whereas if you search for `law` then multiple entries will be
// found except the above entry!
Note:
Node.js version 16 or 18 is required for winkNLP.
The wink-nlp-utils remains available to support the legacy code. Please refer to wink-bm25-text-search version 3.0.1 for wink-nlp-util examples.
API
defineConfig( config )
Defines the configuration from the config object. This object defines following 3 properties:
The
fldWeights(mandatory) is an object where each key is the document's field name and the value is the numerical weight i.e. the importance of that field.The
bm25Params(optional) is also an object that defines upto 3 keys viz.k1,b, andk. Their default values are respectively1.2,0.75, and1. Note:k1controls TF saturation;bcontrols degree of normalization, andkmanages IDF.The
ovFldNames(optional) is an array containing the names of the fields, whose original value must be retained. This is useful in reducing the search space using filter insearch()api call.
definePrepTasks( tasks [, field ] )
Defines the text preparation tasks to transform raw incoming text into an array of tokens required during addDoc(), and search() operations. It returns the count of tasks.
The tasks should be an array of functions. The first function in this array must accept a string as input; and the last function must return an array of tokens as JavaScript Strings. Each function must accept one input argument and return a single value.
The second argument — field is optional. It defines the field of the document for which the tasks will be defined; in absence of this argument, the tasks become the default for everything else. The configuration must be defined via defineConfig() prior to this call.
addDoc( doc, uniqueId )
Adds the doc with the uniqueId to the BM25 model. Prior to adding docs, defineConfig() and definePrepTasks() must be called. It accepts structured JSON documents as input for creating the model. Following is an example document structure of the sample data JSON contained in this package:
{
title: 'Barack Obama',
body: 'Barack Hussein Obama II born August 4, 1961 is an American politician...'
tags: 'democratic nobel peace prize columbia michelle...'
}The sample data is created using excerpts from Wikipedia articles such as one on Barack Obama.
It has an alias learn( doc, uniqueId ) to maintain API level uniformity across various wink packages such as wink-naive-bayes-text-classifier.
consolidate( fp )
Consolidates the BM25 model for all the added documents. The fp defines the precision at
which term frequency values are stored. The default value is 4 and is good enough for most situations. It is a prerequisite for search() and documents cannot be added post consolidation.
search( text [, limit, filter, params ] )
Searches for the text and returns upto the limit number of results. The filter should be a function that must return true or false based on params. Think of it as Javascript Array's filter function. It receives two arguments viz. (a) an object containing field name/value pairs as defined via ovFldNames in defineConfig(), and (b) the params.
The last three arguments limit, filter and params are optional. The default value of limit is 10.
The result is an array of
[ uniqueId, relevanceScore ], sorted on the relevanceScore.
Like addDoc(), it also has an alias predict( doc, uniqueId ) to maintain API level uniformity across various wink packages such as wink-naive-bayes-text-classifier.
exportJSON()
The BM25 model can be exported as JSON text that may be saved in a file. It is a good idea to export JSON prior to consolidation and use the same whenever more documents need to be added; whereas JSON exported after consolidation is only good for search operation.
importJSON( json )
An existing JSON BM25 model can be imported for search. It is essential to call definePrepTasks() before attempting to search.
reset()
It completely resets the BM25 model by re-initializing all the variables, except the preparatory tasks.
Accessors
It provides following accessor methods:
getDocs()returns the Term Frequencies & length of each document.getTokens()returns thetoken: indexmapping.getIDF()returns IDF for each token. Tokens are referenced via their numerical index, which is accessed viagetTokens().getConfig()returns the BM25F Configuration as set up bydefineConfig().getTotalCorpusLength()returns the total number of tokens across all documents added.getTotalDocs()returns total documents added.
Note: these accessors expose some of the internal data structure and one must refrain from modifying it. It is meant exclusively for read-only purpose. Any intentional or unintentional modification may result in serious malfunction of the package.
Need Help?
If you spot a bug and the same has not yet been reported, raise a new issue or consider fixing it and sending a pull request.
About winkJS
WinkJS is a family of open source packages for Natural Language Processing, Statistical Analysis and Machine Learning in NodeJS. The code is thoroughly documented for easy human comprehension and has a test coverage of ~100% for reliability to build production grade solutions.
Copyright & License
wink-bm25-text-search is copyright 2017-22 GRAYPE Systems Private Limited.
It is licensed under the terms of the MIT License.