
wechat_spider
v1.0.9
Published
Wechat Spider
Downloads
29

Readme
wechat_spider
![]()

这个项目是使用打理的方式抓取微信公众账号文章,首先你需要了解一下现在抓取微信公众账号的两种主流方法,请参考我的文章:
所以现在一般有两种做法,一种通过搜狗微信,一种通过代理的方式抓取,这个项目就是使用代理的方式抓取。
我本来是写了更复杂的工具,使用 Node.js 的 anyproxy 加上 php 的 Laravel 框架,完成这些功能,但是某天洗澡的时候终于想通了,我其实把一个工具复杂化了,这个工具本来是很简单的,我给一位媒体朋友指导了一下,他也很快就用起来了。
输出
输出有两个东西,一个是 wechat.sqlite,一个是 wechat.csv,wechat.csv 需要通过命令 wechat_spider csv 来生成。
如下是我的公众账号对应的数据:

表格头解释:
accountName: 公众号名称
author: 作者
title: 文章标题
contentUrl: 文章链接
cover: 文章封面图
digest: 文章摘要
idx: 如果是1,代表的是当天第一篇文章,如果是2,代表当天第二篇文章,以此类推。
sourceUrl: 阅读原文对应的链接
createTime: 文章创建时间
readNum: 阅读数
likeNum: 点赞数
rewardNum: 赞赏数
electedCommentNum: 被选择显示的回复数安装
安装 Node.js
通过网站 https://nodejs.org/zh-cn/ 下载最新版本。
安装 Python
因为里面依赖 sqlite,中间编译的过程需要 python,所以 Windows 的同学一定要安装一下(注意环境变量),否则会出错。
通过网站 https://www.python.org/downloads/ 下载 python
测试 Node 和 Python 安装正确
Mac 在终端下,Windows 在 cmd 下:
$ npm -v
4.3.0
$ python
Python 2.7.6 (default, Nov 18 2013, 15:12:51)
[GCC 4.2.1 Compatible Apple LLVM 5.0 (clang-500.2.79)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>>如果输出以上类似的信息,证明工具已经安装好了。
安装 wechat_spider
$ npm install wechat_spider -g测试 wechat_spider 安装正确
$ wechat_spider --help
Usage: wechat_spider [options]
Options:
-h, --help output usage information
-V, --version output the version number如果输出以上类似信息,证明 wechat_spider 已经安装成功
使用
使用分四步,开启代理,手机设置代理,查看公众账号历史记录,接下来就开始自动抓取了,最后生成 csv。
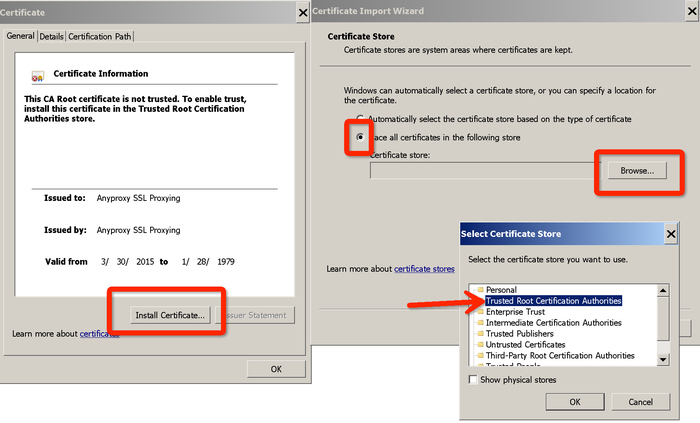
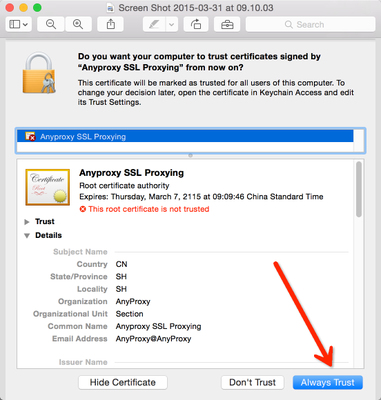
首次打开需要安装证书
第一步:Mac 在终端下,Windows 在 cmd 下打开工具:
$ wechat_spider
首次需要信任证书。
默认会打开证书的文件夹,如果没有打开,浏览器打开 http://localhost:8002/fetchCrtFile ,也能获取rootCA.crt文件,获取到根证书后,双击,根据操作系统提示,信任rootCA:
- Windows
- Mac
第二步:使用手机代理:
首次手机需要安装证书,浏览器打开:http://localhost:8002/qr_root,使用微信扫描二维码,[重要] 用浏览器打开:
然后获取到你电脑的 IP 地址,假设是 192.168.1.5
设置手机代理为电脑:
第三步:选择一个微信公众号,点击查看历史记录
第四步:等待出现页面“一个公众号采集完成”,就可以生成 csv 了
$ wechat_spider csv打赏
我是金马,一个想搞点事情的程序员。如果这个小工具对你有帮助,你可以请我喝杯咖啡,谢谢 :)

LICENSE
MIT.