
vblaze
v1.0.5
Published
Downloads
15
Maintainers
 reevr
reevrReadme
V-blaze
Vblaze is a one of the best worker threads utility library for nodeJs.
Worker threads were introduced in nodeJs to allow users to write code in such a way that , blocking code could be moved to be executed in a seperate thread. Hence keeping the main eventloop unblocked.
This is an in process worker house for doing asynchronous tasks in nodeJs.
There are following features :
- WorkerPool
- WorkerHouse
- Publishers for message brokers
- Nanojob
Worker Pool
This is a WorkerPool instance, a group of workers alloted to do tasks in parallel.
It consists of a enqueue method to push in a job and any of the workers will pick it up and execute the job. Consists of auto respawning feature , if any worker thread dies , it automatically respawns and if the dead worker was processing a job ,then it will be re-executed with the new worker keeping it reliable.
No matter how many times we invoke vblaze(), only one WorkerPool is created.
Worker pool maintains tag for each worker used in reserving workers. By default every worker is set with 'default' tag.
(async () => {
const { WorkerPool } = await vblaze(25); // 25 worker-threads will be created.
/**
Below, we reserve workers in the workerpool using specific tag.
We use this to allot , number of workers for a specific type of task.
eg: In the `tagWorkers` function :
* 'sum', 'multiplcation' and 'data-encode' are the tags passed as first parameter.
* 3, 5 and 4 are passed as the cumber of workers to be alloted to each tag respectively.
note: In this case our worker pool has 25 workers, but you can only reserve 23 out 25 workers for any number of tags. 2 of 25 will always be reserved with 'default' tag. This is to be used by the 'nanoJob'.
**/
WorkerPool.tagWorkers('sum', 3);
WorkerPool.tagWorkers('multiplcation', 5);
WorkerPool.tagWorkers('data-encode', 4);
/**
Lets pass in soe work to the workers for each tag.
**/
const sumFunc = ({ a, b }) => {
return a + b;
}
const multiplcationFunc = ({ a, b }) => {
return a * b;
}
const dataEncodeTaskFilePath = require.resolve('./data-encode-task.js');
const callback = (err, result, workerId) => {
// This callback is callled when the worker completes the task
if (err)
return console.log(err);
console.log(result, workId);
}
WorkerPool.enqueue({ workId: Date.now(), data: { a: 10, b: 5 }, callback, taskSource: { task: sumFunc }, 'sum');
WorkerPool.enqueue({ workId: 'some-random-id', data: { a: 10, b: 5 }, callback, taskSource: { task: multiplcationFunc }, 'multiplcation');
WorkerPool.enqueue({ data: "Some data to be encoded", callback, taskSource: { filePath:dataEncodeTaskFilePath }, 'data-encode');
// workId is optional. If you do not pass a workId, it will automatically generate a workId.
})()Note : If the NODE_ENV environment variable must be set to any other environment other than 'development' to be able to create as many workers required otherwise Vblaze will consider it in 'development environment'. And in 'development' environment , Vblaze allows to create only as many workers as the cpu(s) available.
Nanojob
A co-routine for nodeJs. Allows to run task in seperate thread without blocking the event-loop. Can be called anywhere in the application by passing a function or task file path and its parametes. It returns with a promise which executes the code in a seperate thread and resolve with the processed result.
Note : nanoJob accepts only two parameters , one is the task funtion or task file path and one single parameter. In case of passing multiple parameters , use objects;
Passing a function:
const data = { name, age };
const result = await nanoJob((data) => {
for (let i = 0; i < 1000; i++) {}
return `${data.name} is ${data.age} years old`;
}, data);
or
Passing a task file path:
const path = require('path');
const result = await nanoJob(path.resolve('./taskFile.js'), { name, age });// taskFile.js
module.exports = (data) => {
for (let i = 0; i < 1000; i++) {
console.log('Executing : ', i);
}
return `${data.name} is ${data.age} years old`;
}WorkerHouse
Used to start a job processing unit consuming messages from message queues. Allows to create consumer groups for multiple message brokers like RabbitMq and Redis, with each consumer group having multiple workers reserved from the worker pool. Each consumer group does a certain task. Consumer group reserves workers using tags.
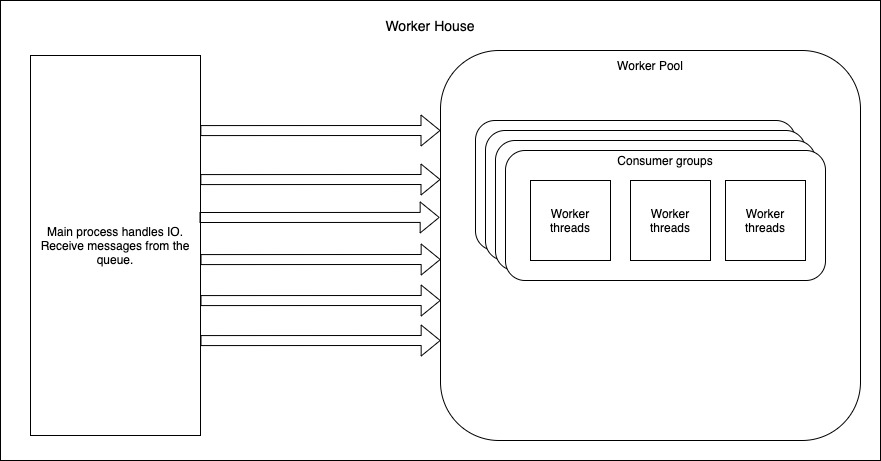
Note : Always two workers in the worker pool are researved with default tags. Can researve only (maxCount - 2 ) workers for consumer groups in total.
// config.js
const config = {};
config.consumerGroups = {
rabbitmq: {
brokerUrl: 'amqp://user:[email protected]:5672',
groups: [
{
options: {
queueName: 'test-queue-1',
taskSource: {
filePath: require.resolve('./task.js')
},
tag: 'test-1-tag'
},
count: 5
},
{
options: {
queueName: 'test-queue-2',
taskSource: {
task: (data) => {
return 'test-queue-2-reev'
}
},
tag: 'test-2-tag'
},
count: 5
},
]
},
redis: {
brokerUrl: 'redis://0.0.0.0:6379',
groups: [
{
options: {
queueName: 'test-queue-3',
taskSource: {
filePath: require.resolve('./task.js')
}
},
count: 5
},
{
options: {
queueName: 'test-queue-4',
taskSource: {
task: (data) => {
return 'reev' + Date.now()
}
}
},
count: 5
}
]
}
};
module.exports = config;// ./task.js
module.exports = async (data) => {
// Do some lengthy operation here
return 'task file output ';
};
(async () => {
const config = require('./config');
const workerHouse = new WorkerHouse(config);
await workerHouse.init();
})()Publisher
Allows to publish job to a certain message queue. It can be Redis publisher or RabbitMq publisher.
Info : There is saturation point for the maxCount you can pass to the worker pool, set as 50 by default. In case you need to increase the saturation count, set the environment variable MAX_THREADS_SATURATION_POINT with a value higher than 50. This allows developer to set the maximum potential of the system used.
MAX_THREADS_SATURATION_POINT=100 node main.jsThis package consists of following methods, objects and object constructor:
- WorkerHouse: constructor
- WorkerPool: object
- getPublisher: function
- nanoJob: function
How to use this library ?
It is necessary to start the worker pool to use all the available features. So we initiate it by passing a parameter for the max number of workers to be allotted in the worker pool.
main.js
const vblaze = require('vblaze');
const config = require('./config');
(async () => {
try {
const { WorkerHouse, WorkerPool, getPublisher, nanoJob } = await vblaze(25);
/** Start a worker house by passing the config object to WorkerHouse constructor */
const workerHouse = new WorkerHouse(config);
await workerHouse.init();
/** Now all the consumers will start processing messages in the queue */
/** To see the contents WorkerPool */
console.log(WorkerPool);
/** Attach nanoJob to global variable to use it anywhere in the application */
global.nanoJob = nanoJob;
/** Execute tasks in seperate thread using nanoJob */
const result = await nanoJob((data) => {
for (let i = 0; i < 1000; i++) {
console.log('Executing : ', i);
}
return `${data.name} is ${data.age} years old`;
}, { name: 'jay', age: '25' });
console.log(result);
/** Initialise Publishers */
const redis1 = await getPublisher('redis', config.consumerGroups.redis.groups[0].options.queueName, config.consumerGroups.redis.brokerUrl);
const redis2 = await getPublisher('redis', config.consumerGroups.redis.groups[1].options.queueName, config.consumerGroups.redis.brokerUrl);
const rabbitmq1 = await getPublisher('rabbitmq', config.consumerGroups.rabbitmq.groups[0].options.queueName, config.consumerGroups.rabbitmq.brokerUrl);
const rabbitmq2 = await getPublisher('rabbitmq', config.consumerGroups.rabbitmq.groups[1].options.queueName, config.consumerGroups.rabbitmq.brokerUrl);
/** Publish jobs to queues initialised above */
for (let i = 0; i< 1000; i++) {
redis1.pushToQueue( 'redis 1')
redis2.pushToQueue( 'redis 2')
rabbitmq1.pushToQueue( 'rabbitmq 1')
rabbitmq2.pushToQueue( 'rabbitmq 2')
}
} catch(err) {
console.log(err);
}
})()config.js
const config = {};
config.consumerGroups = {
rabbitmq: {
brokerUrl: 'amqp://user:[email protected]:5672',
groups: [
{
options: {
queueName: 'test-queue-1',
taskSource: {
filePath: require.resolve('./task.js')
},
tag: 'test-1-tag'
},
count: 5
},
{
options: {
queueName: 'test-queue-2',
taskSource: {
task: (data) => {
return 'test-queue-2-reev'
}
},
tag: 'test-2-tag'
},
count: 5
},
]
},
redis: {
brokerUrl: 'redis://0.0.0.0:6379',
groups: [
{
options: {
queueName: 'test-queue-3',
taskSource: {
filePath: require.resolve('./task.js')
}
},
count: 5
},
{
options: {
queueName: 'test-queue-4',
taskSource: {
task: (data) => {
return 'reev' + Date.now()
}
}
},
count: 5
}
]
}
};
module.exports = config;task.js
const fs = require('fs');
function wait(time) {
return new Promise((resolve, reject) => {
setTimeout(() => resolve(), time)
});
}
module.exports = async (data) => {
await wait(100);
const fileContents = fs.readFileSync(__filename);
fs.readFileSync(__filename);
fs.readFileSync(__filename);
fs.readFileSync(__filename);
fs.readFileSync(__filename);
fs.readFileSync(__filename);
return 'task file output ';
};Lets understand the config file :
consumerGroups:
This is where the complete configuration for starting a worker house goes.
A consumer group can be of two type : redis and rabbitmq.
Every rabbitmq related options are passed as value to 'rabbitmq' propery.
Every redis related options are passed as value to 'redis' propery.
config.consumerGroups = {
rabbitmq: {
/** ConsumerGroupTypeOptions **/
},
redis: {
/** ConsumerGroupTypeOptions **/
}
}A redis and rabbitmq inside consumer has two main properties : brokerUrl and groups.
{
brokerUrl: 'amqp://user:[email protected]:5672',
groups: [
{ /** ConsumerConfig **/ },
{ /** ConsumerConfig **/ }
]
}brokerUrl: This is the connection url to the broker service.groups: This is a list of ConsumerConfigOptions
An object in groups array has options and count.
{
options: {
/** ConsumerConfigOptions **/
},
count: 5
}count: This is the number of workers instances of a particular type of consumer.options: This are details about the queue which consumer must listen to and the code to process the messages.
options consists of an object wuth queueName and taskSource.
{
queueName: '<Name of the queue>',
taskSource: {
/** MessageProcessorSource **/
}
}queueName: This is the name of the queue , that a consumer can listen for messages.taskSource: This is the souce to the code which processes the messages. This can be a anonymous function or a filepath which exports a function . Functions can be asynchrounous.
taskSource consists of an object with filePath and task. :
/** note: Only one of these will be used. `filePath` is given priority over `task` **/
{
filePath: require.resolve('./task.js'),
task: (data) => {
return 'reev' + Date.now()
}
}filePath: This is the absolute path to the file which exports a function to process the message.task: This is a function which processes the message.