
sqlquest
v0.7.1
Published
A sql job runner/DSL
Downloads
56

Readme
sqlquest
Ever wanted to go on an adventure but ended up taking an arrow to the knee? No worries, sqlquest has your back!
Purpose
sqlquest is meant to be a brutally simple SQL job DSL/runner. It's written in coffeescript and is designed to be easy enough to use that non-programmers can make use of it with little training, and engineers can use it for complex tasks. You can have your coffee and drink it too.
Usage
sqlquest is meant to be used from an install in another project. The idea is that you'll create your own 'myawesomequests' package. Example:
$ mkdir myawesomequests
$ cd myawesomequests
$ npm init
... follow instructions
$ npm install --save sqlquest
$ ln -s node_modules/.bin/sqlquest sqlquestWith this symlink, you can run sqlquest from the top level of your project.
Create a directory called quests/. This is where you'll put all your quests.
Each quest is a directory (the name of the quest) with at a minimum either a
.{coffee,js} file or a .sql file at the top level.
You can run quests like so:
$ ./sqlquest awesomequestThis will run the quest in quests/awesomequest/.
Quests
So how do you go on these damned quests? Well, we have a DSL for that!
Create a file, quests/awesomequest/sql/awesome.sql:
CREATE TABLE numbers (
n integer
);
INSERT INTO TABLE numbers VALUES
(1),
(2),
(3),
(4);
SELECT * FROM numbers
WHERE a_number > {{min}};Now create a file called quests/awesomequest/awesome.coffee
Quest = require 'sqlquest'
module.exports =
class AwesomeQuest extends Quest
adventure: ->
@sql file: 'awesome.sql', {min: @opts.min}Now you can run your awesome quest like so:
$ ./sqlquest awesomequest -u myuser -H my.db.com -d mydb -- --min 2or
$ ./sqlquest awesomequest --url postgres://myuser:[email protected]/mydb -- --min 2You should now see sqlquest running each block of sql in your awesome.sql file
one by one, outputting the queries and their execution times. Since we passed an
object as the second arg to @sql the sql is assumed to contain mustache
syntax like {{variable}} which will be filled in with the object's data.
If ya really really wanted, you could just embed the sql in the file itself:
Quest = require 'sqlquest'
module.exports =
class AwesomeQuest extends Quest
adventure: ->
@sql """CREATE TABLE numbers (
n integer
);
INSERT INTO TABLE numbers VALUES
(1),
(2),
(3),
(4);
SELECT * FROM numbers
WHERE a_number > {{min}};""",
min: @opts.minPretty dope, right?
There are other helpers to make your adventure easier.
Inventory
sqlquest has a number of baked in potions to keep you healthy. Take a gander. To dig a bit deeper, sift through the code. Bit of prose in there.
transactions
You can do transactions the normal way, just by shoving BEGIN and such in
place, but there's also a helper for that:
Quest = require 'sqlquest'
module.exports =
class AwesomeQuest extends Quest
adventure: ->
@transaction =>
@sql file: 'foo.sql'
@sql file: 'bar.sql'This simply takes the function passed to it and executes it after running
BEGIN;. If an uncaught error occurs, it will catch and run ROLLBACK; before
throwing the error back up. So, that's a little cooler than doing it yourself,
right?
retries
Transactions are neat, but what if you want to perhaps retry in the event of an error? Well, we've got a spell for that as well:
Quest = require 'sqlquest'
module.exports =
class AwesomeQuest extends Quest
adventure: ->
@retry =>
@sql file: 'foo.sql'
@sql file: 'bar.sql'Does what it says on the tin. When just passed a function, it defaults the number of retries allowed to 10 and the wait between retries to 5000 milliseconds. You can change that.
@retry times: 5, wait: 2000 =>
...Oh, and you can give it an array of regular expressions to only retry on certain matching error messages.
@retry times: 5, wait: 2000, okErrors: [/omg error/], =>
...If you'd like to continue execution of your quest in the event of a failure to
retry after exhausting tries, pass silent: true. This will cause no error
to be thrown regardless of what happens in the retry loop, but will make sure
the exit code is set to 1 when the quest exits to report failure.
little bobby tables
You probably want to see the results of queries sometimes. It's not trivial to output them in a readable way.
Nah, I'm just kidding, we got something for that too:
@table @sql(file: 'foo.sql')That'll output the results as a table. Just like dat.
All together now!
Quest = require 'sqlquest'
module.exports =
class AwesomeQuest extends Quest
adventure: ->
@retry times: 5, wait: 2000, okErrors: [/my silly error/], =>
@transaction =>
@sql file: 'foo.sql', {foo: 1, bar: 2}
@table @sql(file: 'bar.sql')Options
You have access to options passed to sqlquest after --. These are your quest
options. The options will be parsed as best as possible automatically, but you
can also specify your option spec to be given to nomnom
before parsing:
class MyQuest extends Quest
options:
name:
abbr: 'n'
required: true
...In any case, parsed options can be found in @opts.
Simple Parameterized SQL
Don't need an adventure? Well, use a cheat code. If your quest does not have a
<quest>.{coffee,js} file, then no biggie, just drop a sql file in your quest
directory. It'll find the first sql file and it'll just run it. If the file has
mustaches it'll fill 'em in with options passed after --.
Safe Parameterized Queries
If for some reason mustache isn't working out for you and you want to use
node-postgres's safe parameterized queries (which protect against sql injection
attacks), you can use those too. Just use the object-as-first-arg form of @sql
and pass it a params property:
@sql text: "INSERT INTO foo VALUES ($1);", params: [1]The above will replace $1 with the number 1.
Note that unlike with mustache replacements, the outputted query will be not have its variables filled in. I've yet to find a way to get the substituted final query out of node-postgres.
Example Output
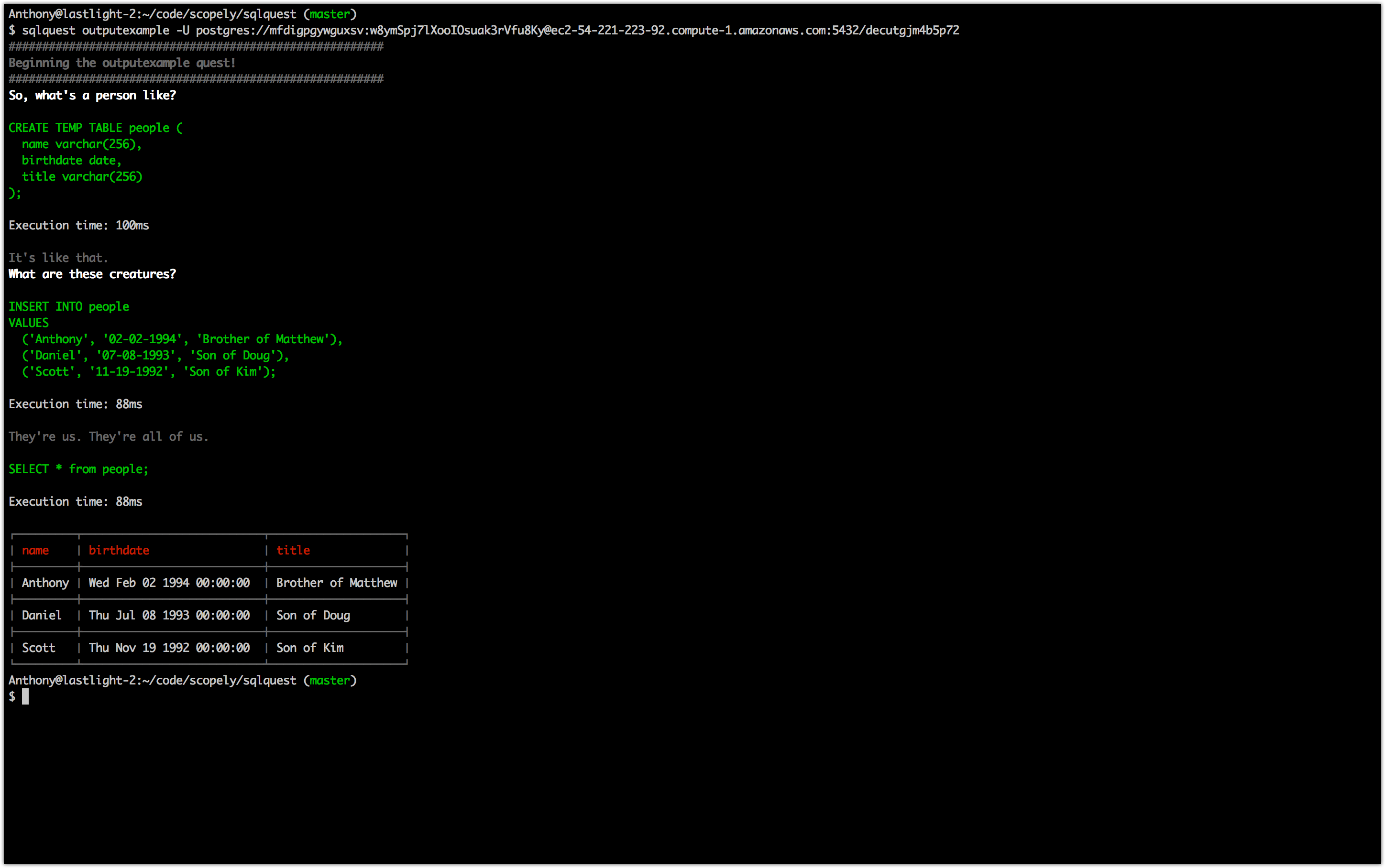
Splitting Queries
When you use sqlquest, you'll notice that it is somehow splitting even large sql files into chunks and timing each individual query. This is because sqlquest has support for hitting an API to split SQL into its individual queries.
Why do we use an external service? Well, because there aren't any good node libs for parsing and dealing with sql code, and there was a better library written in Python with a already running API behind it. I'd rather not have to make this project depend on Python directly, so this seemed like a nice compromise.
The service used by default is sqlformat.org, but this is entirely configurable. sqlformat has an IP-based API limit of 500 requests per hour. I cannot vouch for the security of this API. I encourage you to deploy our open source flask server that does the same thing!
Server Spec
Just implement an endpoint that takes a POST with a sql form parameter
containing a string of sql. It should return, in json:
{
"result": [query1, query2, ...]
}Turning It Off
You can make @sql not split by using the first-arg-is-options format and
passing split: false:
@sql text: "SELECT * FROM bar;SELECT * FROM foo;",
split: falseSupported SQL DBs
- Postgres
- Redshift (written for usage here)
Config
You can specify any of sqlquest's options in a config.toml file, or pass
--config to where the config is.
host = "foo.db.com"
user = "me"
...Plugins
SQLQuest has a simple built in plugin system that can be used to add fucntionality. First of all, here's how you use a plugin:
module.exports =
class MyQuest extends Quest
plugins: [
'sqlquest-reporting'
]
...That's it. The string 'sqlquest-reporting' is the same thing you'd pass to
require to require the plugin module and it is, in fact, what happens under
the hood.
So how does that work? Well, take a look at
sqlquest-reporting. A plugin
is a module that exports one single function that takes the current Quest
object and... does stuff with it.
Quest has a built in addHelper method that plugins can call on the quest
to add their own helper functions. For example, the reporting plugin adds
@report!
Finally, Quest is an EventEmitter. As such, you can capture Quest's
internal events and also add your own in your plugins. Poke around the Quest
class to see which events you can track!
Affqis
SQLQuest 0.7.0 and up supports a new way of connecting to databases. You can use Scopely's Affqis project to connect to databases it supports (currently just hive). Until this is all tested and stable, sqlquest supports the historical method of connecting via node-postgres and your quests will likely continue to work with no change.
Eventually, Affqis will support multiple databases including Redshift/Postgres and as such we'll be able to drop node-postgres.
To configure and use Affqis databases, configure it like so:
[affqis]
host = "localhost"
port = 8080
[affqis.hive]
host = "my.hive-server-host.com"
port = 10000
user = "auser"Then in your quest, you can specify which databases to target:
class MyQuest extends Quest
databases: ["pg", "hive"]
adventure: ->
@sql "select 1" # will run on postgres/redshift
@sql text: "select 1", db: "hive" # will run on hiveNamespacing
If your helpers aren't going to be fairly uniquely named in some way, it's recommended that you namespace your helpers. Basically, instead of adding commonly named helper methods, add one uniquely (like your project name, possibly) named helper that points to a class or a hash – something that you allows for the dot accessor syntax. Folks can then access your plugin via that helper, and you can name your helpers whatever you like:
@myplugin.lol stuffThat said, some of Scopely's own plugins might break this rule a bit. C'mon, we made the darn thing, we should be allowed to stomp all over the namespace, right?!
Organizing Your Quests
The trick here is mostly to remember that you don't need to just have one single
quests directory. You can specify the quests direction via the -q option.
You can organize your quests pretty much however you see fit!