
natural-language-parser
v1.0.0
Published
A parser for the English language in TypeScript
Downloads
2

Readme
Natural Language Parser in Typescript
![]()
The purpose of this tool is to create an AST from a sentence in English. You ca use the generated abstract syntax tree to analyze the semantics of the sentence and use them as an input for a natural language interpreter.
Structure
The rules that describe the language grammar are defined in grammar/BNF.txt - using the Backus–Naur metasyntax. The actual implementation utilizes OOP principals using TypeScript classes.
Usage
Install using npm:
npm i natural-language-parserImport using CommonJS and create an instance:
const Parser = require('natural-language-parser').default
const parser = new Parser()
const parsed = parser.parse('the dog is in the park') // will create a Rule instanceJavaScript API
Import the parser using CommonJS:
const Parser = require('natural-language-parser').defaultparserInstance.parse()
The parse function creates a Rule instance that contains all matched sentence parts as properties:
const parsed = parser.parse('the dog is in the park')outputs an object with the following structure:
verbPhrase: VerbPhraseRule {
type: 'VerbPhrase',
verb: VerbPhraseRule {
type: 'VerbPhrase',
noun: [NounPhraseRule],
verb: [VerbPhraseRule]
},
preposition: [Preposition],
noun: NounPhraseRule {
type: 'NounPhrase',
determiner: [Determiner],
noun: [NounPhraseRule]
}
}parsed.toHumanReadableJSON()
Use the toHumanReadableJSON function to create a JSON:
const parsed = parser.parse('the dog is in the park')
console.log(parsed.toHumanReadableJSON())outputs a JSON object with simplified structure:
{
"VerbPhrase": {
"VerbPhrase": {
"NounPhrase": {
"determiner": "the",
"noun": "dog"
},
"verb": "is"
},
"preposition": "in",
"NounPhrase": {
"determiner": "the",
"noun": "park"
}
}
}CLI
Use the nlp-cli command to parse a sentence:

nlp-cli parse -s "the balrog sleeps in Moria"
will produce:
{
"VerbPhrase": {
"VerbPhrase": {
"NounPhrase": {
"determiner": "the",
"noun": "balrog"
},
"verb": "sleeps"
},
"preposition": "in",
"noun": "Moria"
}
}Configuration
The parser needs a dictionary in order to be able to recognize different words as verbs, nouns. prepositions etc. There is a built-in dictionary in the parser. It supports the most common English verbs, nouns, prepositions, determiners and conjunctions.
A dictionary.js file
If you need to specify a custom dictionary - you can create a dictionary.js file located in the root of your project:
node_modules/ index.js dictionary.js ...
The dictionary file must contain values for all required word classes supported by the parser:
module.exports = {
nouns: ['road'],
verbs: ['drive'],
conjunctions: ['and'],
prepositions: ['in'],
determiners: ['the'],
modalVerbs: ['should'],
}If some of the above listed word classes is missing the parser will use the built-in dictionary. The dictionary is not case insensitive.
Custom dictionary file
If you want to use a dictionary from a custom-named file that is not in the root of the repo - you can use a nlpconfig.js file. The config file must be located in the root of the repo and it must have the dictionaryPath property:
module.exports = {
dictionaryPath: 'some-folder/dictionary-custom.js'
}How it Works
The parser accepts an input in English, breaks it down to its building components and builds a syntax tree representing the hierarchical structure of a sentence.
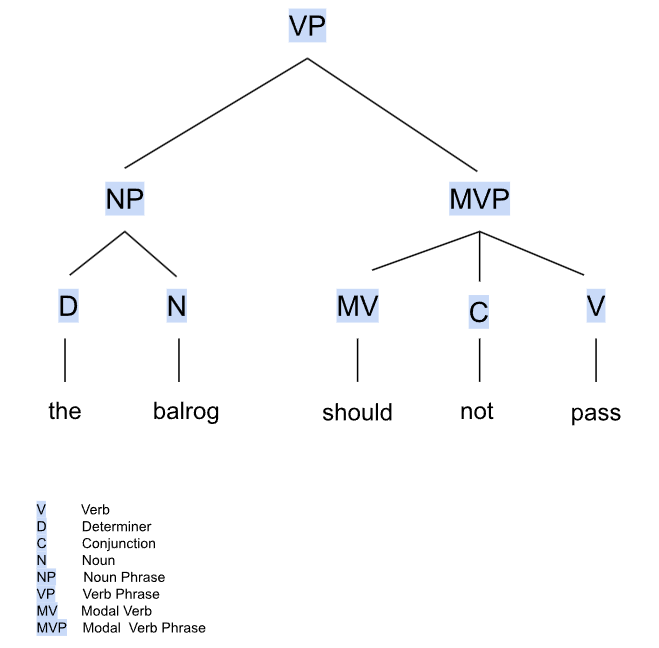
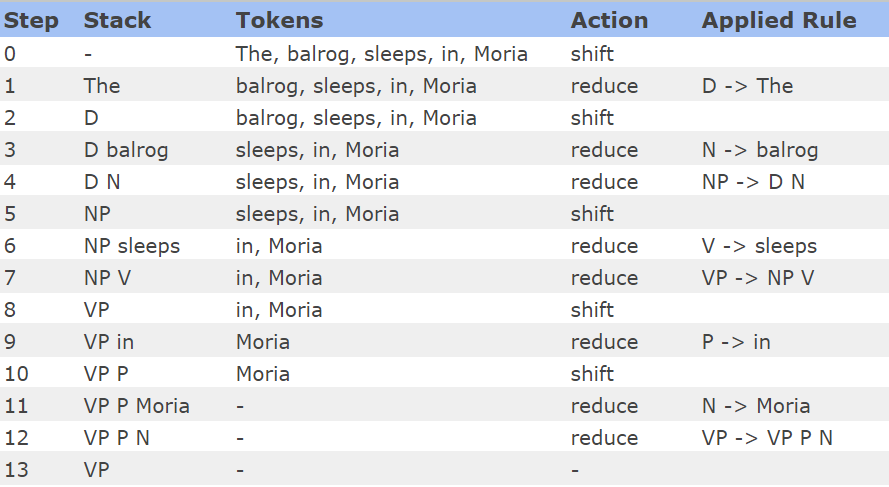
It separates the input into tokens - this process is called tokenization. Then recursively checks if the tokens can be substituted with items from the grammar's set - this is called the production operation. The production rules are defined in the grammar of the parser. For example a noun phrase is made up of a determiner and and a noun - "The sun" - NP -> D N. A verb phrase is made up of a verb and a noun phrase - "The sun rises" - VP -> V NP | NP V. Once there are no possible productions the parser stops and outputs the result. It uses a bottom up(shift-reduce) parsing algorithm - pushes the next word of the input sentence to a stack(the shift operation) and checks if a sequence of tokens corresponds to the right hand side of a production rule and substitutes it with the left hand side of that rule(the reduce phase) - will replace V NP with VP:
For more information regarding natural language parsing refer to Natural Language Processing with Python .
Limitations & Known Issues
This is an experimental project. As such it has limitations and issues:
- It does not fully support the English language. The supported grammar is described in Backus–Naur form in the BNF.txt file.
- It will not produce a full tree if a token is not recognized by the dictionary
- Compound-complex sentences are not fully supported; currently only a sentence that consists of [
<verb_phrase><conjunction><verb_phrase>] will be parsed successfully:
nlp-cli parse -s "the balrog should not pass and sleeps in Moria"will output:
AST: {
"conjunction": "and",
"verbPhraseA": {
"VerbPhrase": {
"NounPhrase": {
"determiner": "the",
"noun": "balrog"
},
"ModalVerbPhrase": {
"modalVerb": "should",
"conjunction": "not",
"verb": "pass"
}
}
},
"verbPhraseB": {
"VerbPhrase": {
"verb": "sleeps",
"preposition": "in",
"noun": "Moria"
}
}
}Everything else will output a single Rule instance - the last token that was reduced:
nlp-cli parse -s "the balrog should not pass and sleeps in Moria and should not sleep"will output:
AST: sleep