
molehill
v0.2.9
Published
Webcrawler for data mining and unification purposes
Downloads
12
Maintainers
 rnd7
rnd7Readme
Molehill
Molehill is a webcrawler for repetitive data mining and unification purposes. It simulates a browser environment, mimics user behaviour, extracts data and downloads binaries.
It comes in different flavours. You can interact using its CLI, Webservice or GUI, automate it using shell scripts, or even use it as library with your node.js project.
It strongly depends on puppeteer, commander and express.
Warning
If you use the Molehill Webservice be sure not to expose it to the Internet. There is not authentication or any kind of filesystem access restriction. Always use an authentication layer if you need to access the GUI over the Internet. Molehill is not designed as public Web Frontend! Everybody who has access owns your computer, really.
Legal Notice
Depending on the site you are crawling and what you do with the gathered data there might be legal problems. I do not encourage to do any illegal acts with this software.
Installation
You need node and npm installed on your machine. It should work on all platforms that are supported by puppeteer. I only tested it on a ubuntu linux and a windows 10 machine.
Install as Application.
npm -i molehill -gInstall as local library
npm -i molehillCLI
The Commandline Interface provides different commands to work with Molehill collections, start the crawler, a webservice or even a graphical user interface.
Main Command
Using npx. Even if this will probably work without installation, I recommend to install Molehill as Application.
npx molehillExecute from dir using shell
./bin/molehill
Commandline Options
No logs nor outputs.
-s, --silentOutput json like raw data only. Primitives are preserved. Use this if you need to work with the std-out
-r, --rawTurn on verbose debug logs
-d, --debugSub Commands
Molehill is using git like subcommands.
npx molehill subcommand --option
npm run subcommand -- --option
./bin/molehill.js subcommand --optionlocate
Locate Application Data
locateExample
npx molehill locate
npm run locate
./bin/molehill.js locatelocate-collection
Locate a collection
locate-collection <collection>Example
npx molehill locate-collection 3fed53f7986155353b41006a4d720a23
npm run locate-collection 3fed53f7986155353b41006a4d720a23
./bin/molehill.js locate-collection 3fed53f7986155353b41006a4d720a23list-collections
List all collections
list-collectionsExample
npx molehill list-collections
npm run list-collections
./bin/molehill.js list-collectionscreate-collection
Create a new collection
create-collection <name>Example
npx molehill create-collection "Collection Name"
npm run create-collection "Collection Name"
./bin/molehill.js create-collection "Collection Name"locate-config
Locate config file of collection
locate-config <collection>Example
npx molehill locate-config 3fed53f7986155353b41006a4d720a23
npm run locate-config 3fed53f7986155353b41006a4d720a23
./bin/molehill.js locate-config 3fed53f7986155353b41006a4d720a23list-items
List all items of a collection
list-items <collection>Example
npx molehill list-items 3fed53f7986155353b41006a4d720a23
npm run list-items 3fed53f7986155353b41006a4d720a23
./bin/molehill.js list-items 3fed53f7986155353b41006a4d720a23view-items
View all items of a collection
view-items <collection>Example
npx molehill view-items 3fed53f7986155353b41006a4d720a23
npm run view-items 3fed53f7986155353b41006a4d720a23
./bin/molehill.js view-items 3fed53f7986155353b41006a4d720a23view-item
View an item within a collection
view-item <collection> <item>Example
npx molehill view-item 3fed53f7986155353b41006a4d720a23 91461306968c82a610245b690db3bed7
npm run view-item 3fed53f7986155353b41006a4d720a23 91461306968c82a610245b690db3bed7
./bin/molehill.js view-item 3fed53f7986155353b41006a4d720a23 91461306968c82a610245b690db3bed7locate-item
Locate an item within a collection
locate-item <collection> <item>Example
npx molehill locate-item 3fed53f7986155353b41006a4d720a23 91461306968c82a610245b690db3bed7
npm run locate-item 3fed53f7986155353b41006a4d720a23 91461306968c82a610245b690db3bed7
./bin/molehill.js locate-item 3fed53f7986155353b41006a4d720a23 91461306968c82a610245b690db3bed7crawl-collection
Start crawling using pages defined in collection config
crawl-collection <collection>Example
npx molehill crawl-collection 3fed53f7986155353b41006a4d720a23
npm run crawl-collection 3fed53f7986155353b41006a4d720a23
./bin/molehill.js crawl-collection 3fed53f7986155353b41006a4d720a23remove-collection
Remove a collecition
remove-collection <collection>Example
npx molehill remove-collection 3fed53f7986155353b41006a4d720a23
npm run remove-collection 3fed53f7986155353b41006a4d720a23
./bin/molehill.js remove-collection 3fed53f7986155353b41006a4d720a23gui
Start Graphical User Interface
guiCommandline Options
Configure Webserver Port. Defaults to 8080
-p, --portExample
npx molehill gui --port 3000
npm run gui -- --port 3000
./bin/molehill.js gui --port 3000server
Start Webservice
serverCommandline Options
Configure Webserver Port. Defaults to 8080
-p, --portExample
npx molehill server --port 3000
npm run server -- --port 3000
./bin/molehill.js server --port 3000Webservice
To start the webservice use the molehill server command.
By default the webservice is listening to Port 8080.
http://localhost:8080Fetch a list of all collections ids
GET /api/collectionFetch metadata of all collections
GET /api/collectionsCreate new Collection
POST /api/collection
{
"name": "Collection Name"
}Fetch Collection Metadata
GET /api/collection/:cidRemove a Collection
DELETE /api/collection/:cidFetch a list of all item ids in collection
GET /api/collection/:cid/itemFetch metadata of all items in collection
GET /api/collection/:cid/itemsDelete all items and binaries of a collection
DELETE /api/collection/:cid/itemsFetch collection config
GET /api/collection/:cid/configUpdate collection config
PUT /api/collection/:cid/configUpdate collection metadata
PUT /api/collection/:cid/metaFetch collection item
GET /api/collection/:cid/item/:iidEvaluate scheme that matches collection item
GET /api/collection/:cid/item/:iid/schemeDelete Collection Item
DELETE /api/collection/:cid/item/:iidGet file used within collection
GET /api/collection/:cid/data/:fileGet Crawler Status
GET /api/crawlerLongpoll for Crawler Status changes
GET /api/crawler/pollGet list of Crawler Task Queue ids
GET /api/crawler/taskGet all Crawler Tasks
GET /api/crawler/tasksGet Downloader Status
GET /api/downloaderLongpoll for Downloader Status changes
GET /api/downloader/pollGet list of Downloader Task Queue ids
GET /api/downloader/taskGet all Downloader Tasks
GET /api/downloader/tasksStart crawling the config pages of given collection
POST /api/crawler/start/:cidHTML client
You can use a Client to interact with the webservice. If you use the gui subcommand a window of the chromium browser shipped with Molehill is opened to display the HTML Client. You might also use the server subcommand to start the webservice and afterwards navigate to http://localhost:8080 using a browser of your choice.
Endpoint serving the client.
GET /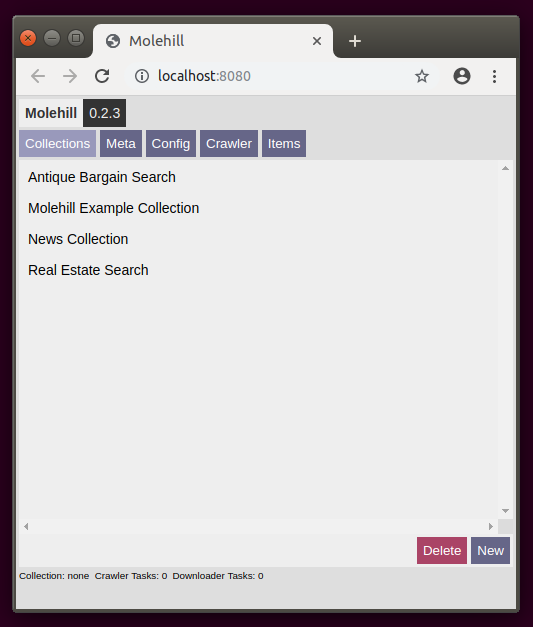
The Startscreen of the client displayed in the browser shipped with Molehill.
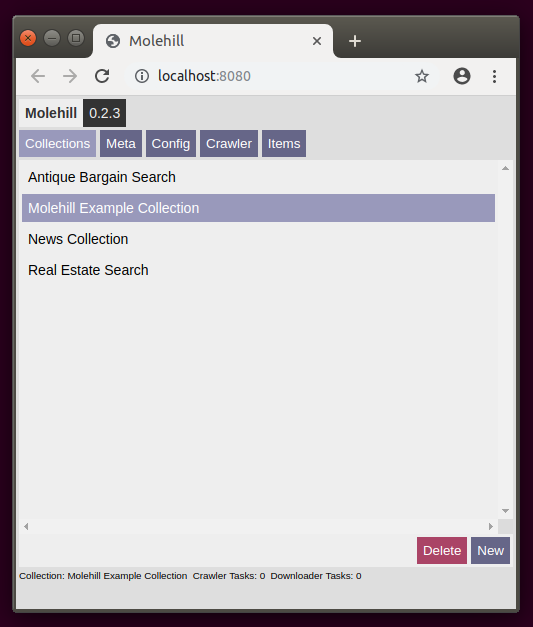
Click on a collection in order to select it. Click on new to create a new one.
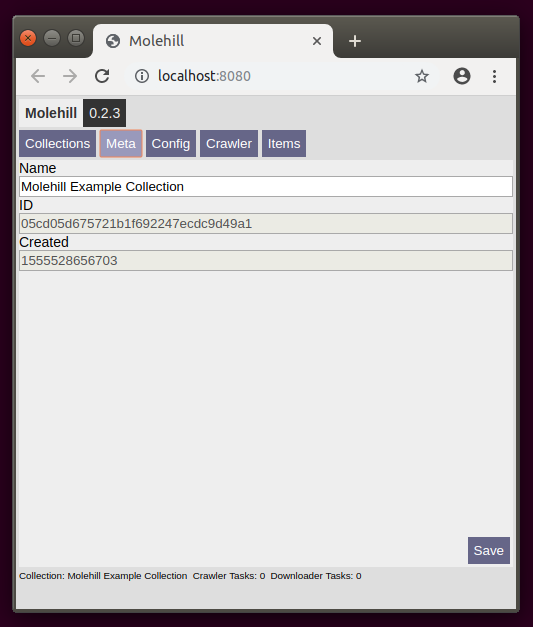
Change the name of the selected collection. Click save to store changes.
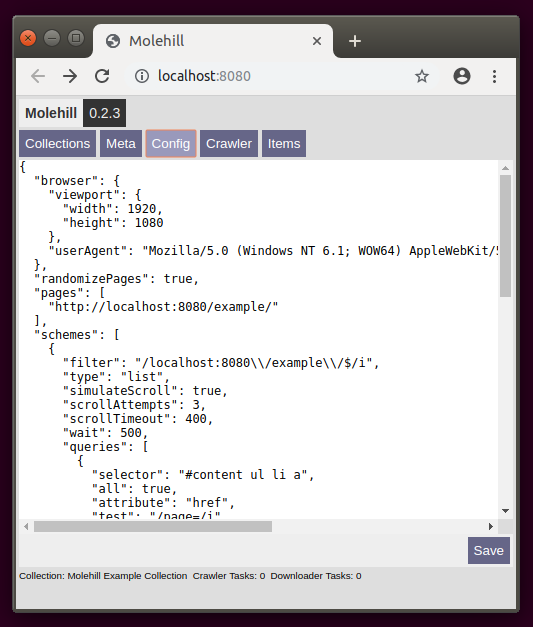
You can edit the config file of the selected collection using the built in editor.
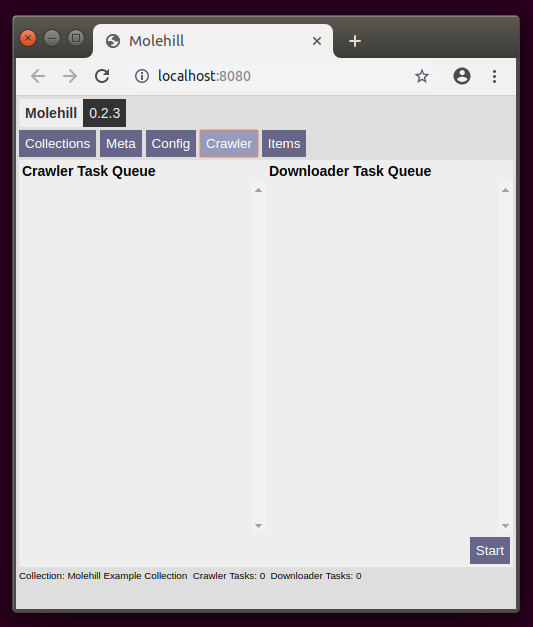
Start the crawler by clicking on start.
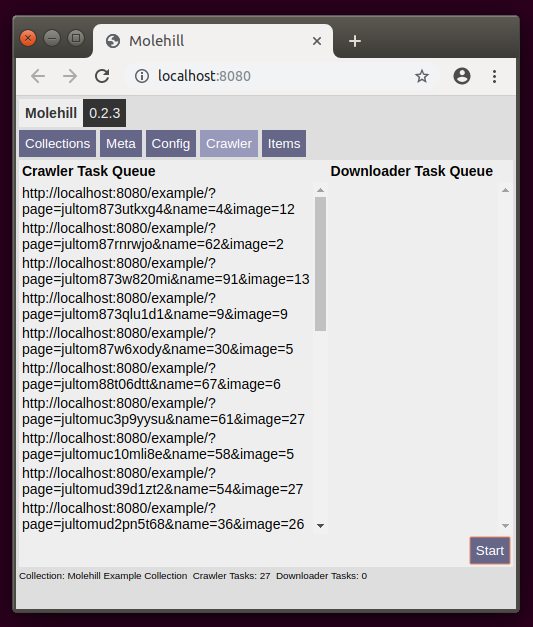
Watch the crawler processing its queue. The small status text in the footer keeps you informed. By default three pages are crawled in parallel. The queue shows only tasks that are currently not processed.
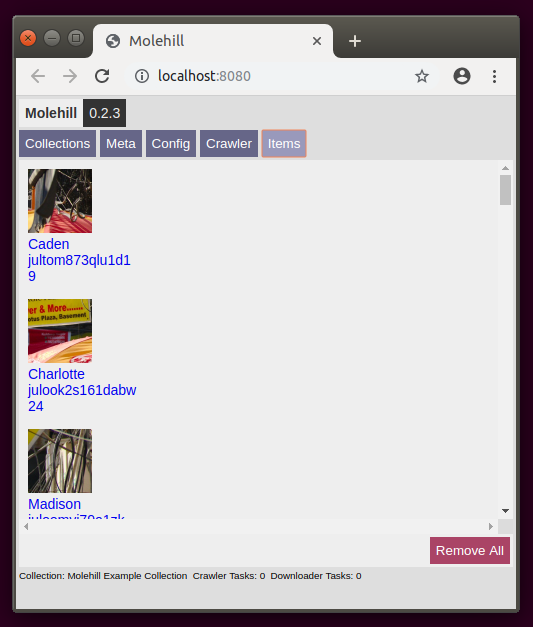
The resulting unified data displayed in a list.
Included Example Page
To test the crawler and provide valid endpoints for the default config, Molehill is shipped with a simple Example Page. Everytime you visit this page unique links are generated. The crawler will treat them as unique items and extract the data according to the queries defined in the matching scheme. When called with parameters the example page will no longer list random entries but show an result page with the item defined by the url parameters.
List View
Endpoint serving the example list
GET /example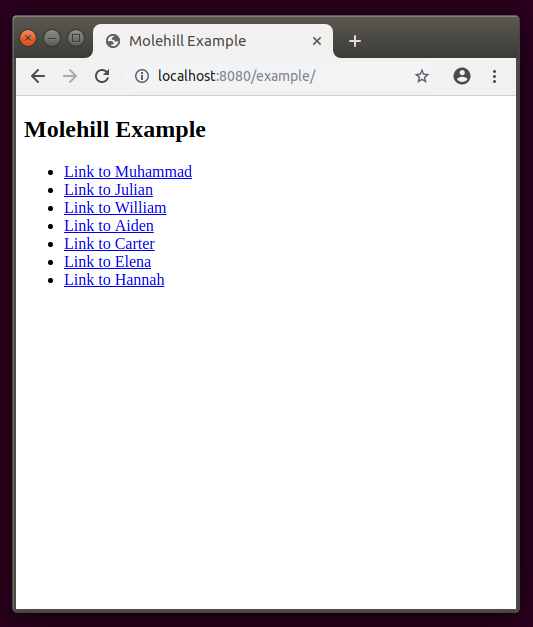
Item View
Endpoint serving parametric example entries.
GET /example/?page=julook2s161dabw&name=24&image=8
App Data
Molehill stores its data including all db entries and files downloaded by the crawler within the shared local userspace.
Ubuntu
/home/username/.local/share/molehill/App Data Structure
- settings.json
+ collection
+ 69096a6ad7c2406b7c2b4c5b1121ac36
+ data
- 3d2ff36bc3e3016a786e339eef173b58.jpg
+ db
- 2c2b38a6285ecb19caa120c729afa76c.json
- 2c9187d7591be2c7145793812fc95284.json
- config.json
- meta.jsonConfig
Defaults
The Default Config will be added to each new Collection you create. You can edit it manually by modifying the settings.json file within the App Data Directory. Using the default config the included Molehill Example Page will be crawled. A random List with links to virtual pages is generated. The crawler processes all of them, extracts the data according to the scheme queries, downloads the images and finally creates unified Collection Items.
Example
{
"browser": {
"viewport": {
"width": 1920,
"height": 1080
},
"userAgent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.83 Safari/537.1"
},
"pages": [
"http://localhost:8080/example/"
],
"schemes": [
{
"filter": "/localhost:8080\\/example\\/$/i",
"type": "list",
"simulateScroll": true,
"scrollAttempts": 3,
"scrollTimeout": 400,
"wait": 500,
"queries": [
{
"selector": "#content ul li a",
"all": true,
"attribute": "href",
"test": "/page=/i",
"key": "links",
"follow": true
}
]
},
{
"filter": "/localhost:8080\\/example\\/\\?/i",
"type": "item",
"wait": 500,
"store": true,
"queries": [
{
"key": "image",
"selector": "#content div.item > img",
"attribute": "src",
"test": "/\\.(jp(e)?g|gif|png)/i",
"download": true,
"display": "image"
},
{
"key": "name",
"selector": "#name",
"attribute": "textContent",
"display": "value"
},
{
"key": "id",
"selector": "#content p.id",
"test": "/[a-z0-9]+/",
"match": "/Id:\\s([a-z0-9]+)/",
"attribute": "textContent",
"display": "value"
},
{
"key": "value",
"selector": "#content input[name=value]",
"attribute": "value",
"display": "value"
}
]
}
]
}Browser Section
These settings are passed to the headless browser instance for every page in the collection.
Example
"browser": {
"viewport": {
"width": 1920,
"height": 1080
},
"userAgent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.83 Safari/537.1"
}Pages section
These are the entry points used by the crawler. You have to provide a scheme that defines a filter to match the url. Without a matching scheme the url is ignored. In this case the included Molehill Example Page will be used as starting point.
Example
"pages": [
"http://localhost:8080/example/"
]Schemes Section
You can provide multiple schemes to match different sites. The url is matched against the filter. Processed top down the first match wins.
The filter might be any regex. Unfortunately you have to escape backslashes, since those are reserved in json files and thats what to config file is.
The type does not have any effect but helps tracking down results.
You can use simulateScroll to mimic user scroll behaviour, especially useful for pages that only load visible content. The scrollAttempts define how often the crawler scrolls to the end of the page. The scrollTimeout defines a delay between the single scrollAttempts.
You can use wait to define an amount of milliseconds the crawler waits before querying the page. Sometimes useful if the content is fetched after the page is rendered.
If you want to create and persist the matched page as collection Item you must set store to true.
You can use multiple queries to extract data.
Example
"schemes": [
{
"filter": "/localhost:8080\\/example\\/$/i",
"type": "list",
"simulateScroll": true,
"scrollAttempts": 3,
"scrollTimeout": 400,
"wait": 500,
"store": true,
"queries": []
}
]Queries section
Every scheme might contain multiple queries. Queries are data extraction tasks applied to the page matched by the scheme.
Use the selector to query the page. It uses the standard querySelector syntax to select the first matching DOM Element. If you set all to true all matching Elements are selected and the query result will be an array.
You have to provide an attribute. This defines which method is used to extract the content of the Element. Possible values are href, textContent, innerHTML, value and any other HTML Element property.
The key defines the key in the Collection Item Element the data is stored in.
Provide a json escaped regular expression as test an all non matching values will be ignored.
If the value returned by the query needs to be truncated you can use a regular expression with on capture group as match.
Set follow to true if you want the crawler to process the query result as page url. You don't need to store the Item matched by the scheme in order to do so. Pages stored in the Collection will not be processed a second time.
If you want the Crawler to download, whatever is returned treating the query result as url and making a get request set download to true. The result will be stored as binary in the collections data folder and linked as value of the given key within the colleciton item representing the page matched by the scheme.
The display property defines how the query result will be rendered. By now, possible values are only image and value.
Example
"queries": [
{
"selector": "#content ul li a",
"all": true,
"attribute": "href",
"test": "/page=/i",
"key": "links",
"follow": true
},
{
"key": "image",
"selector": "#content div.item > img",
"attribute": "src",
"test": "/\\.(jp(e)?g|gif|png)/i",
"download": true,
"display": "image"
},
{
"key": "name",
"selector": "#name",
"attribute": "textContent",
"display": "value"
},
{
"key": "id",
"selector": "#content p.id",
"test": "/[a-z0-9]+/",
"match": "/Id:\\s([a-z0-9]+)/",
"attribute": "textContent",
"display": "value"
}
]API
You might also use Molehill as library to integrate it or its parts in your software.
The main exposes a init method. This is invoked by the molehill cli entrypoint. If you don't call it Molehill will stay passive while you can still use its parts.
require('molehill').init()Collection
The Collection module provides almost all Molehill functionality. It utilizes the Crawler and the Downloader to fetch, extract and download data.
require('molehill').CollectionStatic Properties
cache
indicesStatic Methods
init()
setPath(str)
setDefaultConfig(config)
getBasepath(id)
crawl(cid)
list()
remove(id)
clone(id, name)
create(name, config)
sync(id)
syncAll()Crawler
The Crawler module is a task worker that fetches websites and queries DOM Elements.
require('molehill').CrawlerEvents
IDLE,
PROCESS
CHANGEStatic Properties
tasksStatic methods
stop()
addTask(url, config)
addTasks(urls, config)
findScheme(url, config)
processQueryResult(value, query)
processQueryResults(values, query)
simulateScroll(page, attempts, timeout)
queryPage(page, scheme)
processTask(url, config)
processTasks()
getStats()
on(eventName, fn)
off(eventName, fn)
once(eventName, fn)Downloader
The Downloader is a task worker that simply downloads binaries, hashes the url to use as name and stores them at a given location.
require('molehill').DownloaderEvents
CHANGEStatic Properties
tasksStatic methods
getFilepath(url, path)
addTask(url, path)
processTask(url, path)
processTasks()
getFilename(url)
getStats()
on(eventName, fn)
off(eventName, fn)
once(eventName, fn)FSDB
Simple document oriented File System Data Base. Manages keys and json files on the harddisk.
require('molehill').FSDBInstance
Basically a wrapper that persists the path and reuses metadata.
new FSDB(path)Methods
getDBPath()
getFilePath(id)
exists(id)
put(id, data)
assign(id, data)
remove(id)
fetch(id)
list()Static Methods
getDBPath(path)
getFilePath(path, id)
exists(path, id)
put(path, id, data)
assign(path, id, data)
remove(path, id)
fetch(path, id)
list(path)Logger
Nifty little logger with tracing capabilities used for CLI output and debugging.
require('molehill').LoggerBasic logging methods
fn(...args)
fn.show = true
fn.color = 'bgBlue'
fn.method = logcmd(...args)
cmd.show = true
cmd.color = 'bgCyan'
cmd.method = logapi(...args)
api.show = true
api.color = 'bgBlueBright'
api.method = logerror(...args)
error.show = true
error.color = 'bgRed'
error.method = errorwarn(...args)
warn.show = true
warn.color = 'bgYellow'
warn.method = warn;status(...args)
status.show = true
status.color = 'bgGreen'
status.method = logoutput(...args)
output.show = true
output.color = 'bgBlack'
output.method = logOutput and formatting
print(...args)
print.silent = falselog(...args)
log.RAW = "raw"
log.JSON = "json"
log.CLI = "cli"
log.style = true
log.silent = false
log.tier = true
log.time = true
log.trace = true
log.stack = false
log.file = true
log.margin = true
log.outputFormat = log.CLIraw(...args)
raw.silent = false
raw.delimiter = ','
raw.linefeed = '\n'Webservice
The Molehill webservice.
require('molehill').WebserviceStatic Methods
start(port)
stop()filesystem
Filesystem utility methods. Basically a simple async await abstraction and generalization.
require('molehill').filesystemStatic Methods
remove(path)
listDirectory(path)
isDirectory(path)
listSubDirectories(path)
verifyFile(path)
loadFile(path)
saveFile(path, data)
loadJSON(path)
saveJSON(path, data)
saveJS(path, name, data)License
See the LICENSE file for software license rights and limitations (GPL-v3).