
eld
v1.0.1
Published
Fast and accurate natural language detection. Detector written in Javascript. Efficient language detector, Nito-ELD, ELD.
Downloads
13,009
Maintainers
 nitotm
nitotmReadme
Efficient Language Detector
![]()
![]()
Efficient language detector (Nito-ELD or ELD) is a fast and accurate language detector, is one of the fastest non compiled detectors, while its accuracy is within the range of the heaviest and slowest detectors.
It's 100% Javascript (vanilla), easy installation and no dependencies.
ELD is also available in Python and PHP.
Install
- For Node.js
$ npm install eld- For Web, just download or clone the files
git clone https://github.com/nitotm/efficient-language-detector-js
How to use?
Load ELD
- At Node.js REPL
const { eld } = await import('eld')- At Node.js
import { eld } from 'eld' // use .mjs extension for version <18- At the Web Browser
<script type="module" charset="utf-8">
import { eld } from './src/languageDetector.js' // Update path.
/* code */
</script>- To load the minified version, which is not a module
<script src="minified/eld.M60.min.js" charset="utf-8"></script>Usage
detect() expects a UTF-8 string, and returns an object, with a 'language' variable, with a ISO 639-1 code or empty string
console.log( eld.detect('Hola, cómo te llamas?') )
// { language: 'es', getScores(): {'es': 0.5, 'et': 0.2}, isReliable(): true }
// returns { language: string, getScores(): Object, isReliable(): boolean }
console.log( eld.detect('Hola, cómo te llamas?').language )
// 'es'- To reduce the languages to be detected, there are 2 options, they only need to be executed once. (Check available languages below)
let langSubset = ['en', 'es', 'fr', 'it', 'nl', 'de']
// Option 1
// Setting dynamicLangSubset(), detect() executes normally but finally filters the excluded languages
eld.dynamicLangSubset(langSubset) // Returns an Object with the validated languages of the subset
// to remove the subset
eld.dynamicLangSubset(false)
// Option 2
// The optimal way to regularly use the same subset, is using saveSubset() to download a new database
eld.saveSubset(langSubset) // ONLY for the Web Browser, and not included at minified files
// We can load any Ngrams database saved at src/ngrams/, including subsets. Returns true if success
await eld.loadNgrams('ngramsL60.js') // eld.loadNgrams('file').then((loaded) => { if (loaded) { } })
// To modify the preloaded database, edit the filename loadNgrams('filename') at languageDetector.js- Also, we can get the current status of eld: languages, database type and subset
console.log( eld.info() )Benchmarks
I compared ELD with a different variety of detectors, since the interesting part is the algorithm.
| URL | Version | Language | |:----------------------------------------------------------|:--------------|:-------------| | https://github.com/nitotm/efficient-language-detector-js/ | 0.9.0 | Javascript | | https://github.com/nitotm/efficient-language-detector/ | 1.0.0 | PHP | | https://github.com/pemistahl/lingua-py | 1.3.2 | Python | | https://github.com/CLD2Owners/cld2 | Aug 21, 2015 | C++ | | https://github.com/google/cld3 | Aug 28, 2020 | C++ | | https://github.com/wooorm/franc | 6.1.0 | Javascript |
Benchmarks: Tweets: 760KB, short sentences of 140 chars max.; Big test: 10MB, sentences in all 60 languages supported; Sentences: 8MB, this is the Lingua sentences test, minus unsupported languages.
Short sentences is what ELD and most detectors focus on, as very short text is unreliable, but I included the Lingua Word pairs 1.5MB, and Single words 880KB tests to see how they all compare beyond their reliable limits.
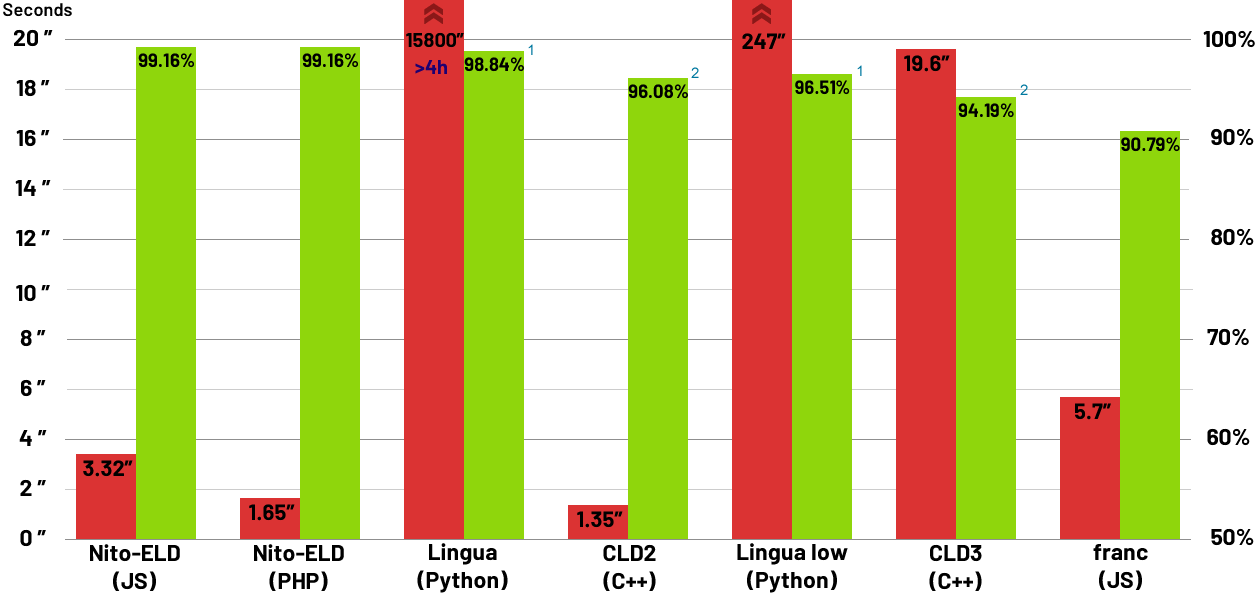
These are the results, first, accuracy and then execution time.
1. Lingua could have a small advantage as it participates with 54 languages, 6 less.
2. CLD2 and CLD3, return a list of languages, the ones not included in this test where discarded, but usually they return one language, I believe they have a disadvantage.
Also, I confirm the results of CLD2 for short text are correct, contrary to the test on the Lingua page, they did not use the parameter "bestEffort = True", their benchmark for CLD2 is unfair.
Lingua is the average accuracy winner, but at what cost, the same test that in ELD or CLD2 is below 6 seconds, in Lingua takes more than 5 hours! It acts like a brute-force software. Also, its lead comes from single and pair words, which are unreliable regardless.
I added ELD-L for comparison, which has a 2.3x bigger database, but only increases execution time marginally, a testament to the efficiency of the algorithm. ELD-L is not the main database as it does not improve language detection in sentences.
For a client side solution, I included an all-in-one detector+Ngrams minified file, of the standard version (M), and XS which still performs great for sentences. The XS version only weights 865kb, when gzipped it's only 245kb. The standard version is 486kb gzipped.
Here is the average, per benchmark, of Tweets, Big test & Sentences.
Languages
These are the ISO 639-1 codes of the 60 supported languages for Nito-ELD v1
'am', 'ar', 'az', 'be', 'bg', 'bn', 'ca', 'cs', 'da', 'de', 'el', 'en', 'es', 'et', 'eu', 'fa', 'fi', 'fr', 'gu', 'he', 'hi', 'hr', 'hu', 'hy', 'is', 'it', 'ja', 'ka', 'kn', 'ko', 'ku', 'lo', 'lt', 'lv', 'ml', 'mr', 'ms', 'nl', 'no', 'or', 'pa', 'pl', 'pt', 'ro', 'ru', 'sk', 'sl', 'sq', 'sr', 'sv', 'ta', 'te', 'th', 'tl', 'tr', 'uk', 'ur', 'vi', 'yo', 'zh'
Full name languages:
Amharic, Arabic, Azerbaijani (Latin), Belarusian, Bulgarian, Bengali, Catalan, Czech, Danish, German, Greek, English, Spanish, Estonian, Basque, Persian, Finnish, French, Gujarati, Hebrew, Hindi, Croatian, Hungarian, Armenian, Icelandic, Italian, Japanese, Georgian, Kannada, Korean, Kurdish (Arabic), Lao, Lithuanian, Latvian, Malayalam, Marathi, Malay (Latin), Dutch, Norwegian, Oriya, Punjabi, Polish, Portuguese, Romanian, Russian, Slovak, Slovene, Albanian, Serbian (Cyrillic), Swedish, Tamil, Telugu, Thai, Tagalog, Turkish, Ukrainian, Urdu, Vietnamese, Yoruba, Chinese
Future improvements
- Train from bigger datasets, and more languages.
- The tokenizer could separate characters from languages that have their own alphabet, potentially improving accuracy and reducing the N-grams database. Retraining and testing is needed.
Donate / Hire
If you wish to Donate for open source improvements, Hire me for private modifications / upgrades, or to Contact me, use the following link: https://linktr.ee/nitotm