
dsub
v1.2.0
Published
An awesome subtitles downloader.
Downloads
2

Readme
dsub
An awesome subtitles downloader.
FAQ
What it does?
It downloads subtitles for movies and TV shows.
Which subtitles sources does it use?
Right now it uses OpenSubtitles and the plan is to add more sources in the future.
How it works?
First, it tries to do an exact match for the video files you're searching subs for.
If no subs are found, it runs a query using the video filename.
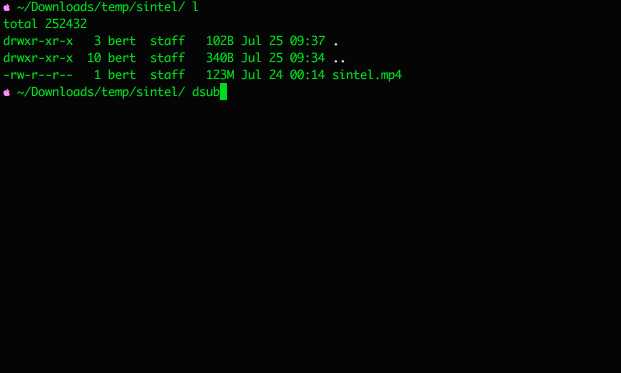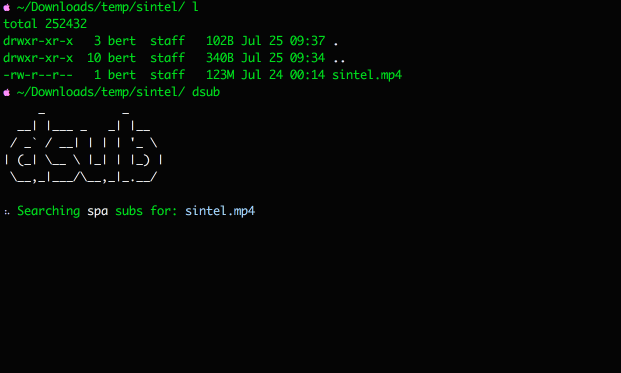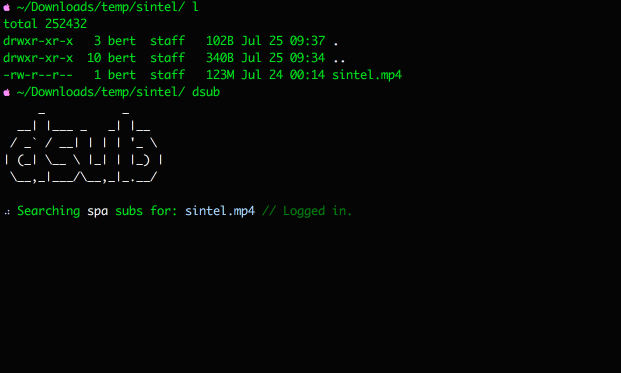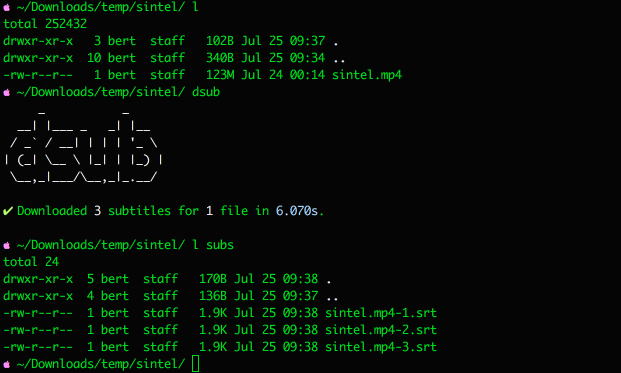
Subs are downloaded in the subs folder by default, where they are automatically
read by VLC, one of the best video players out there.
CLI install
npm install -g dsub
Dependency install
npm install --save dsub
CLI usage
dsub: Download subs for all video files in current folder.
dsub --name='Awesome Movie': Download subs for a movie named Awesome Movie.
dsub --verbose: Displays errors when it finishes.
dsub --debug: Displays debug info.
dsub --ignore='sample|extra': Ignore files with sample or extra in the filename.
dsub --src='~/Movies/sintel': Download subs for all files in ~/Movies/sintel.
Defaults to current directory.
dsub --dest='~/Movies/sintel': Download subs in ~/Movies/sintel.
Defaults to ./subs, creates the folder if it doesn't exist.
dsub --lang='spa': Download spanish subs. Use these language codes as reference.
dsub --all: Ignores exact matching and uses a query to download all available subs.
Programatic usage
const Dsub = require('dsub')
const dsub = new Dsub({name, src, dest, lang, noExtract, debug, ignore})
dsub
.on('searching', ({file}) => {
// Called each time searching starts.
// Searching is sequential for each video file found.
// `file` is the current video file we're searching subs for.
})
.on('login', ({file, token}) => {
// Called after logged in to subtitles provider.
// `file` is the current video file we're searching subs for.
// `token` is the subtitles provider token used for searching.
})
.on('downloading', ({file, total}) => {
// Called every time a subtitles file starts downloading.
// `file` is the current video file we're downloading subs for.
// `total` is the amount of subs there are left to be downloaded for this file.
})
.on('extracting', ({file, total}) => {
// Called when extracting subs.
// `file` is the current video file we're extracting subs for.
// `total` is the amount of subs there are left to be extracted for this file.
})
.on('cleanup', ({file, total}) => {
// Called once after all subs have been downloaded for this file.
// The cleanup process involves deleting all compressed files.
// `file` is the current video file we're cleaning up for.
// `total` is the amount of files needed to cleanup.
})
.on('partial', ({time, total, file}) => {
// Called once after all subs finished downloading and extracting for this file.
// Occurs after cleanup.
// `time` is the total amount of time elapsed while processing this file.
// `total` is the total amount of downloaded subs for this file.
// `file` is the current video file we downloaded subs for.
})
.on('done', ({time, totalFiles, totalSubs}) => {
// Called after all subs where downloaded for all files.
// `time` is the total amount of time elapsed while processing all files.
// `totalFiles` is the total amount of processed video files.
// `totalSubs` is the total amount of downloaded subs for all files.
})
.on('empty', ({file}) => {
// Called when there are no subs for this video file.
// `file` is the current video file we searched subs for.
})
.on('error', (error) => {
// Called when errors occur.
// `error` is the error object or string.
})
.download() // Calling `download()` starts the download process.Enjoy!