
crawlyx
v2.2.3
Published
Crawlyx is an open-source command-line interface (CLI) based web crawler built using Node.js. It is designed to crawl websites and extract useful information like links, images, and text. It is lightweight, fast, and easy to use.
Downloads
119
Maintainers
 ritikchoure
ritikchoureReadme
Crawlyx
Crawlyx is a powerful CLI-based web crawler built using Node.js that can help you extract valuable data from websites and improve your website's SEO ranking. Whether you're a marketer, SEO professional, or web developer, Crawlyx can be an essential tool in your arsenal for website analysis, optimization, and monitoring.
With Crawlyx, you can easily crawl any website and extract data such as page titles, meta descriptions, headings, links, images, and more. You can also use Crawlyx to analyze the internal linking structure of a website, identify broken links, duplicate content, and other issues that may be hurting the SEO ranking of your website.
In addition, Crawlyx provides a custom report feature that allows you to generate detailed reports based on the data extracted from websites. You can generate reports in various output formats such as CSV, JSON, and HTML, and customize the report to include or exclude specific data fields.
With the HTML report feature, you can generate visually appealing reports that provide insights into the SEO ranking, user experience, and other aspects of a website. These reports can help you make data-driven decisions and optimize your website for better performance.
So if you want to improve your website's SEO ranking, optimize your content, and stay on top of changes to your website, Crawlyx is the tool for you. Try Crawlyx today and unleash the power of web crawling!

![]()


Demo
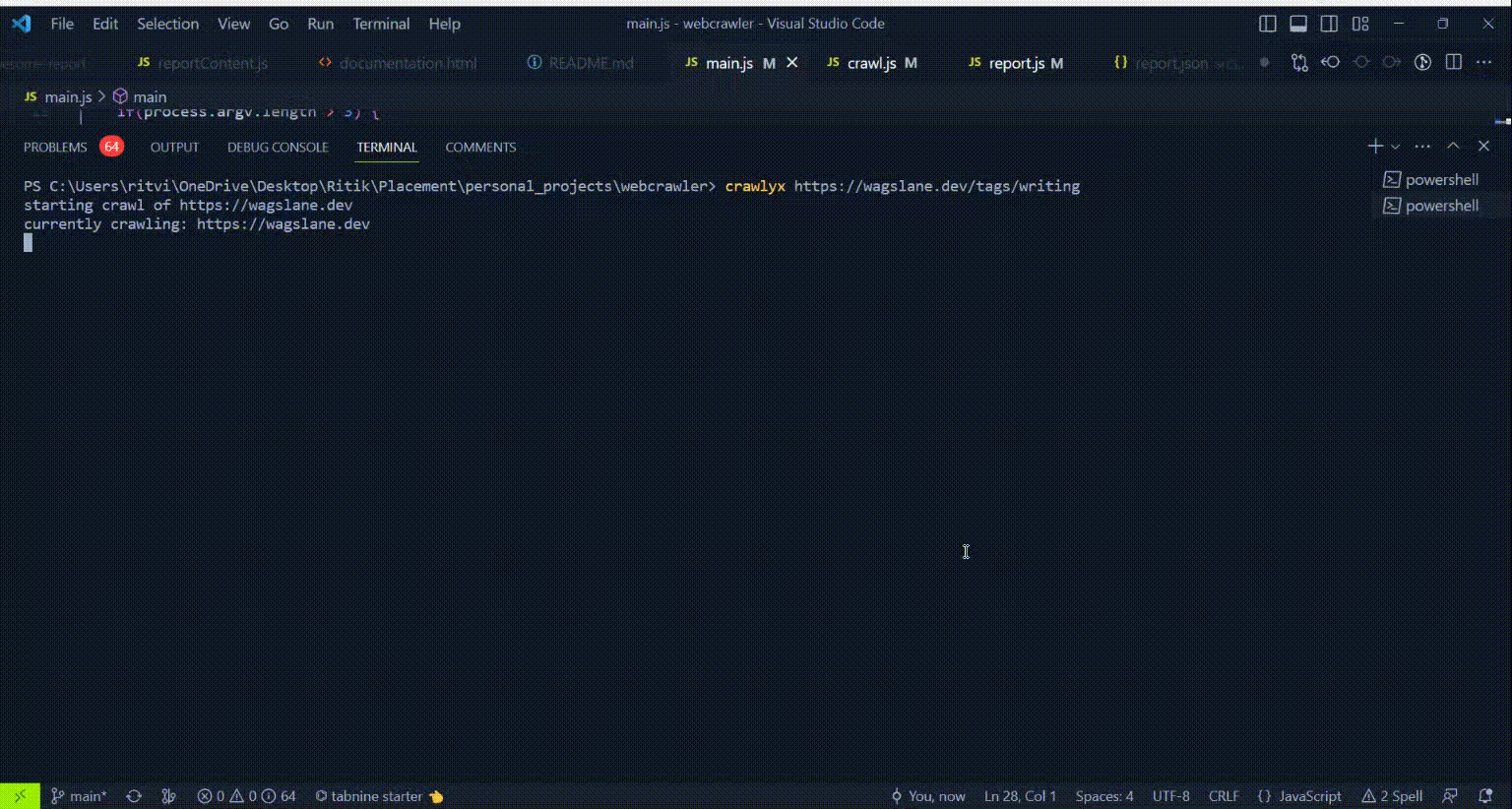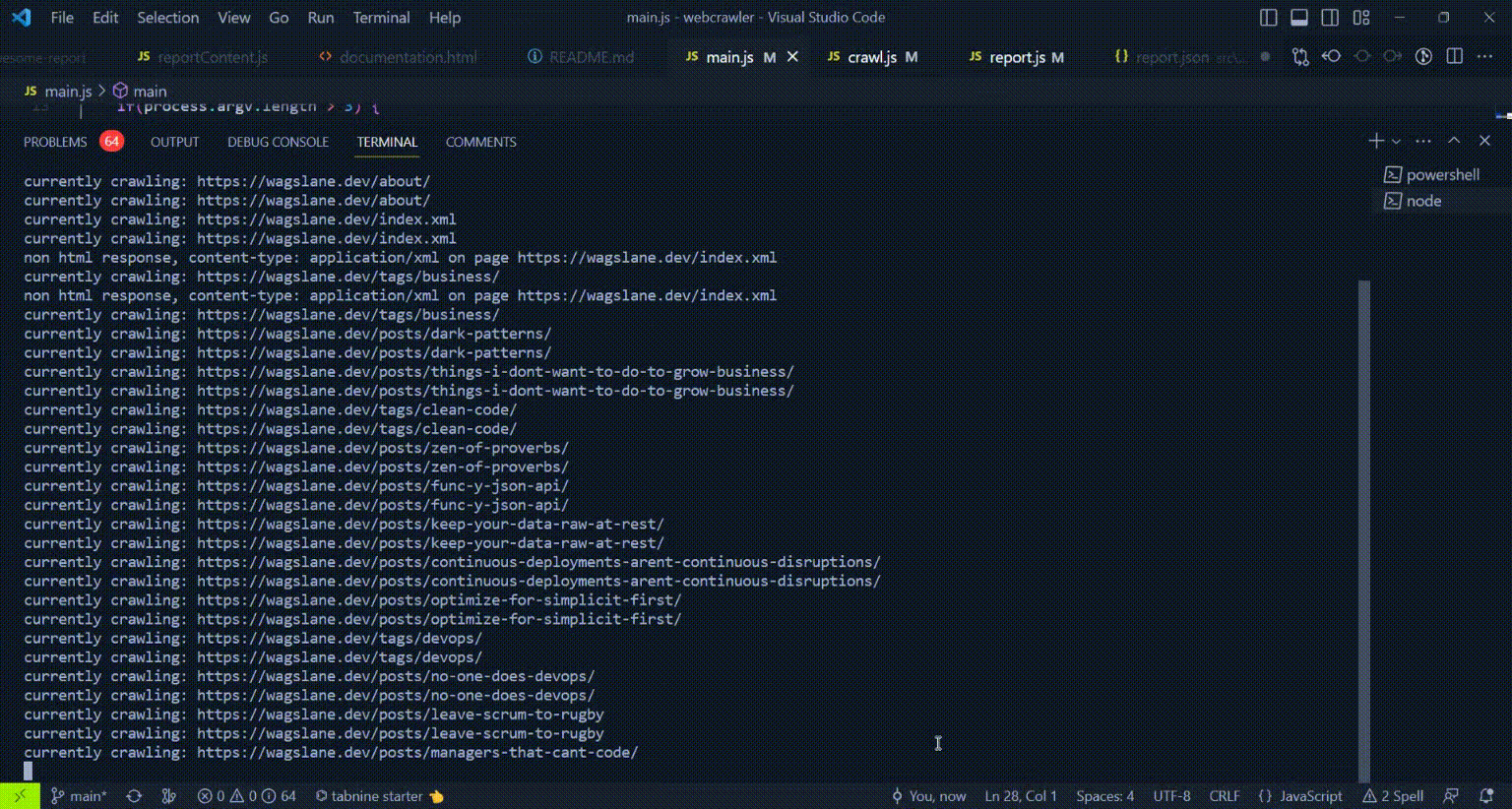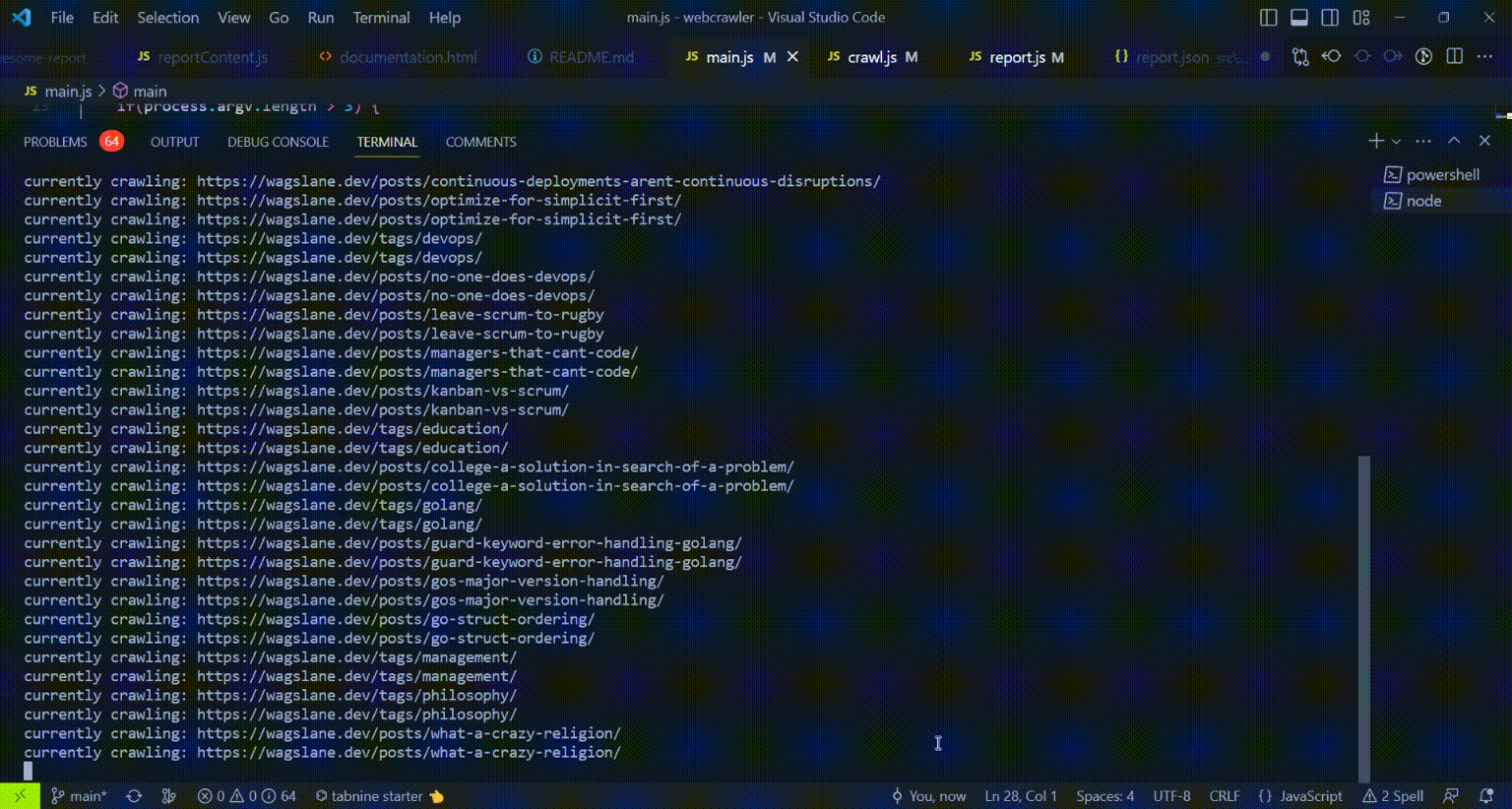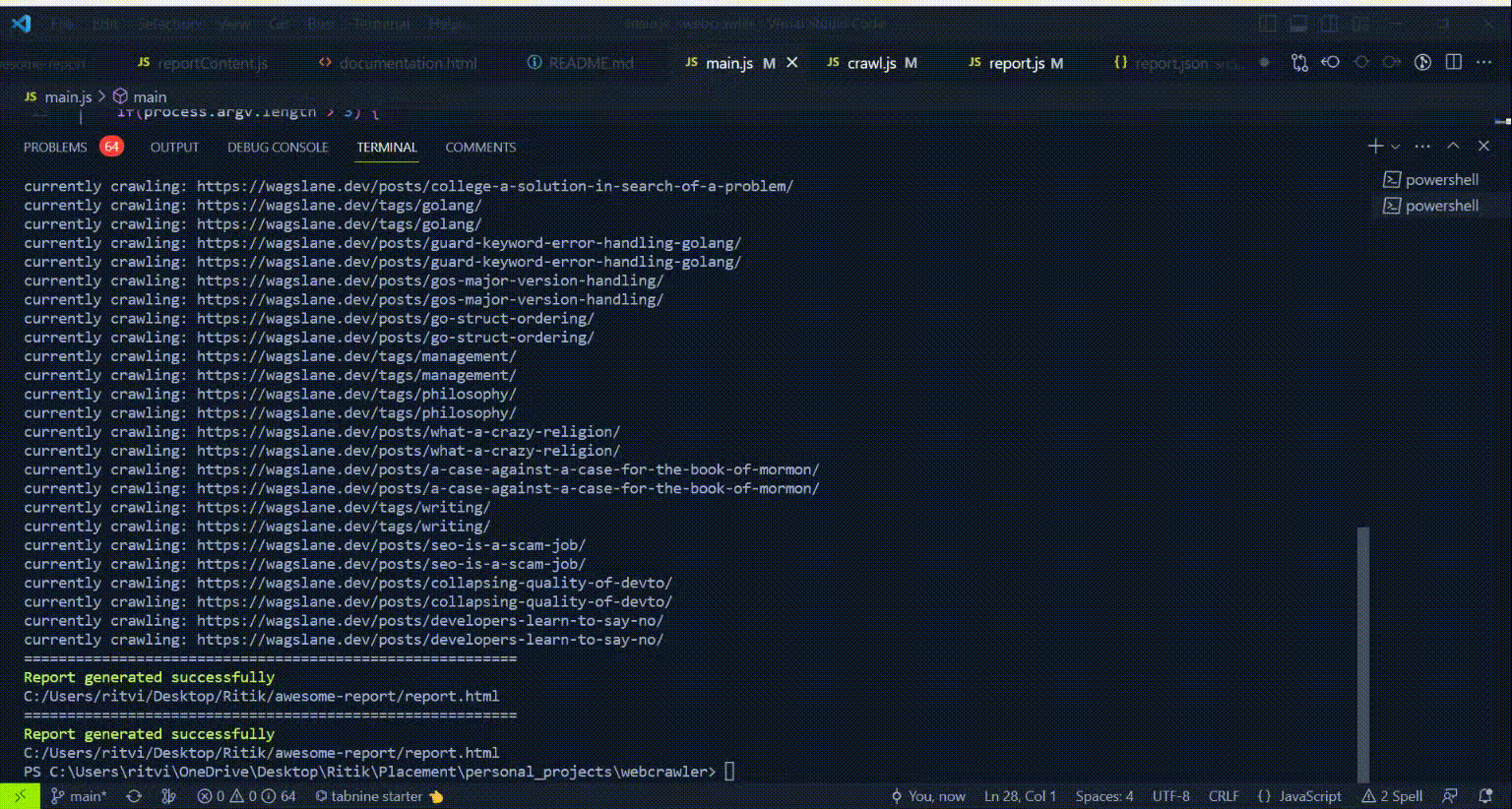
Installation
npm i -g crawlyxmake sure you install it globally.
To check successful installation of crawlyx, open command prompt or windows terminal.
Type in your cmd -
crawlyx --versionInstallation troubleshoot
If you are still getting an installation error after the global installation, You can change the execution policy of PowerShell to allow running unsigned scripts. Open your terminal in vs code or whatever ide you use and run the following command
Set-ExecutionPolicy -Scope CurrentUser -ExecutionPolicy UnrestrictedCLI Usage
Start crawling by the following command -
crawlyx <valid-website>Features
Web Crawling: Crawlyx can crawl any website and extract valuable data such as page titles, meta descriptions, headings, links, images, and more.
SEO Analysis: Crawlyx can analyze the internal linking structure of a website, identify broken links, duplicate content, missing tags, and other issues that may be hurting the SEO ranking of your website.
Customizable Reports: Crawlyx provides a custom report feature that allows you to generate reports in various output formats such as CSV, JSON, and HTML. You can customize the report to include or exclude specific data fields and generate visually appealing reports that provide insights into the SEO ranking, user experience, and other aspects of a website.
User-Friendly CLI: Crawlyx has a user-friendly command-line interface that makes it easy to use, even for those who are not familiar with web crawling or programming.
Cross-Platform Support: Crawlyx works on multiple platforms, including Windows, Mac, and Linux.
Open-Source: Crawlyx is an open-source project, which means that its source code is freely available for anyone to use and contribute to.
With these features, Crawlyx can be a valuable tool for marketers, SEO professionals, web developers, and anyone who needs to extract data from websites or monitor changes to a website.
Operating System supports
| Windows (7, 8, 10, and Server versions) | macOS (10.10 and higher) | Linux (Ubuntu, Debian, Fedora, CentOS, etc.) | | ------ | ---- | ------- | | ✅ | ✅ | ✅ |
How it works
Parsing the command-line arguments: Crawlyx uses the popular commander.js library to parse the command-line arguments and options. This allows users to specify the website URL and other options.
Crawling the website: Crawlyx uses the
fetchfunction andJSDOMlibrary to crawl the website and extract data such as page titles, meta descriptions, headings, links, images, and other elements. This data is stored in an internal data structure that can be processed and exported later.Analyzing the website: Crawlyx uses various algorithms to analyze the internal linking structure of the website, identify broken links, duplicate content, missing tags, and other issues that may be hurting the SEO ranking of the website.
Generating the report: Crawlyx uses the specified output format to generate the report. This can be in CSV, JSON, or HTML format, depending on the user's choice. The report contains various data fields such as page title, meta description, headings, links, images, and other data extracted from the website.
Contribution
Note - Give a ⭐ to this project
- Fork this repository (Click the Fork button in the top right of this page, click your Profile Image)
- Clone your fork down to your local machine
git clone https://github.com/your-username/crawlyx.git- Create a branch
git checkout -b branch-name- Make your changes (choose from any task below)
- Commit and push
git add .
git commit -m 'Commit message'
git push origin branch-name- Create a new pull request from your forked repository (Click the New Pull Request button located at the top of your repo)
- Wait for your PR review and merge approval!
- Star this repository if you had fun!
For more information, Please read CONTRIBUTING.md for details on our code of conduct, and the process for submitting pull requests to us.
Attribution
You can use this badge for attribution in your project's readme file.
[](https://theritikchoure.github.io/crawlyx/docs/) Author
Feedback
If you have any feedback/queries, please reach out to us at [email protected]
License
This package is licensed under the © MIT license