
archiver-for-google-keep
v0.0.4
Published
Scrapes notes and checklists from Google Keep™ and writes them out as JSON and markdown archive/backup files. This tool is not affiliated or endorsed by Google™. Google Keep™ is a trademark of Google.
Downloads
23
Maintainers
 jmort253
jmort253Readme
Archiver for Google Keep™
The purpose of this project is to make it easier to backup data in Google Keep where the official Google Keep API, the unofficial gkeepapi, and Google Takeout are not viable options for backing up the data.
While there is an official Google Keep API, at this time it's still not well documented and is advertised to be enterprise-only. There's an unofficial API called gkeepapi, which suffers from login issues. I've not been able to get it working reliably since May 2022, and there's not a definitive answer I can find to solving the problem.
This alternative to the Google Keep API uses the webdriverio package to scrape content via the Google Chrome or Chromium browser and then write the output to JSON and markdown files.
Unbeknownst to many, WebdriverIO can connect to Chrome or Chromium without a WebDriver, using the DevTools protocol. Additionally, it doesn't require custom builds of the browser, like Playwright does. This simplifies the setup and eliminates the need to depend on Chromedriver or on custom-built browsers.
Getting Started
For best results, install the application as a global npm module:
$ npm i archiver-for-google-keep -gTo run the application, run the following command:
$ keep-archiverNOTE: Alternatively, you can clone the project and use npm start to run the program.
A Google Chrome or Chromium browser will launch.
On the first run, you'll need to login to Google Keep with your credentials. Afterwards, the credentials are cached in the devtools-data-dir Chrome profile.
NOTE: On subsequent runs, logging in shouldn't be necessary, unless you've deleted/corrupted the
devtools-data-dirfolder.
After logging in, as well as on subsequent runs, go back to the terminal, and you'll see a prompt with instructions:
ATTENTION: Please follow these steps to export/backup your data
- Login to Google Keep
- Click on the label you wish to backup.
- Press ENTER to start the backup (or press 'q' to quit).
prompt: Continue with the backup? (Press ENTER):
If you want to backup everything in Google Keep, just press ENTER. But if you only want to backup notes from a single label, first click on that label to load those cards, and then press ENTER.
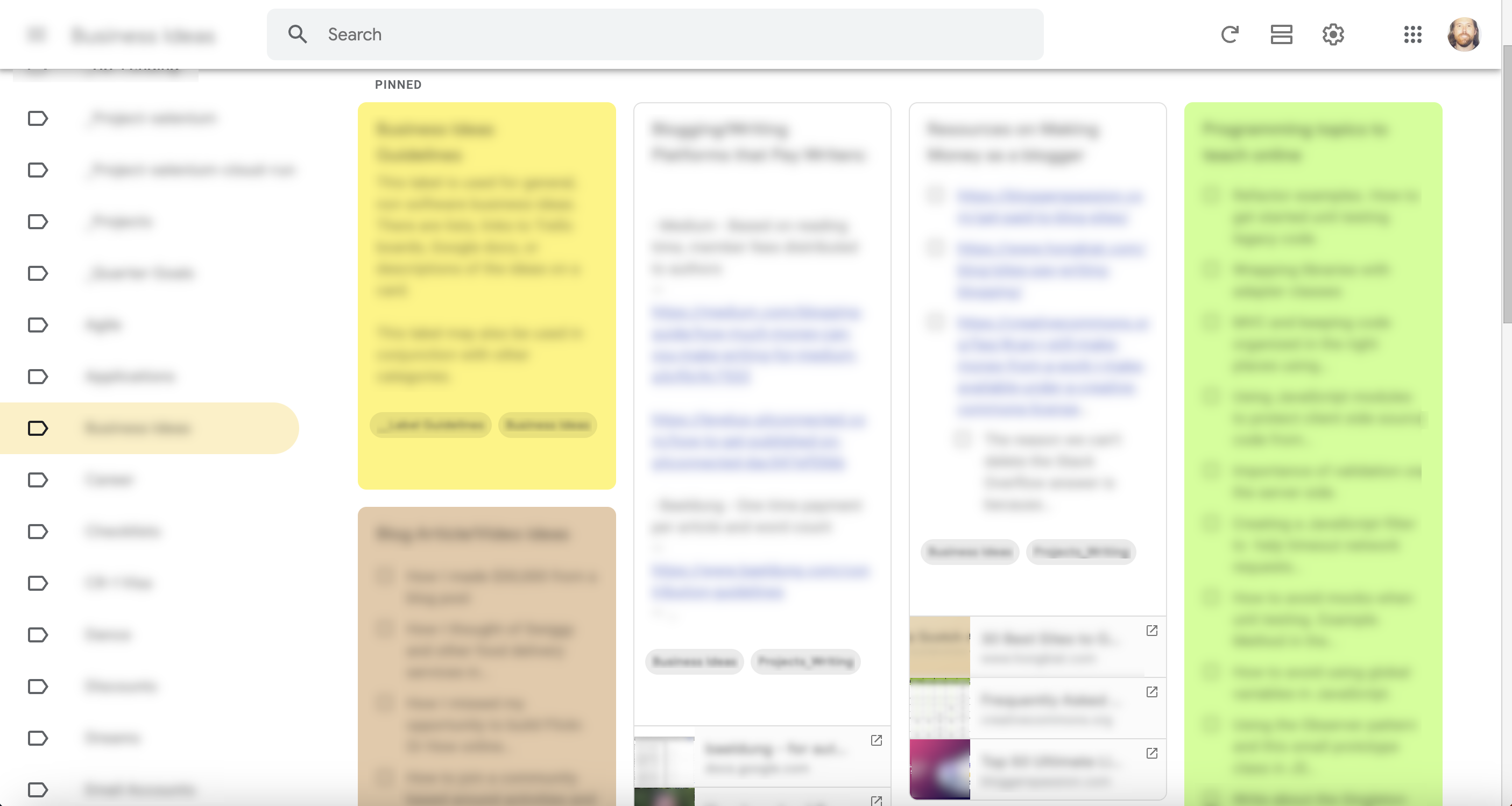
You'll now observe WebdriverIO scroll all of the cards into view. In order to scrape the data, everything must be loaded on the page.
Once all of the content is loaded, the system will select each card individually, in reverse order, and extract the following contents:
- title
- body
- keepUrl
- lastEditedTime
- createdTime
- labels
- isPinned
- color
The extracted information is then written to JSON and markdown files in the ./output folder. Here's an example:
scrummaster-initiatives.md
---
title: "ScrumMaster initiatives"
lastEditedTime: Edited Jan 6, 2019
createdTime: Created Jan 6, 2019
labels: Ideas,Scrum
isPinned: false
color: rgb(255, 255, 255)
keepUrl: https://keep.google.com/#LIST/<redacted>
---
- [ ] Scrummaster podcast.
- [ ] Topic: what tools do you use as a ScrumMaster?
- [ ] Guest facilitator - SM from a team which facilitated retro for another team.
- [ ] What ideas do our scrummasters have or experiments to try? What is an experiment you did in 2018?
Once the archive is completed, rename the /output folder and move it to a safe place. For example:
$ mv output ~/Documents/my-keep-backupOther Protocols and Options
By default, this tool connects WebdriverIO to Chrome/Chromium via the newer DevTools protocol. This means less overhead and less dependencies. This means Chromedriver, or a Selenium server, is not required in order for this tool to connect to the browser.
However, if for some reason you wish to use Chromedriver (or Selenium server) to connect this tool to Chrome/Chromium, then simply start Chromedriver listening on port 4444. WebdriverIO first attempts to use the WebDriver protocol on default port 4444 before falling back to DevTools:
Chromedriver
$ chromedriver --port=4444If Chromedriver opens a different version of Chrome than what is opened with DevTools, then you may also want to use a different user-data-directory:
$ KEEP_DATA_DIR=./webdriver-data-dir npm startSelenium Server
This can also be used with a Selenium server, as long as it's running on port 4444.
$ java -jar selenium-server.jar standaloneBe sure to specify an absolute path for the data directory:
$ KEEP_DATA_DIR=$PWD/webdriver-data-dir npm startConnecting to Remote Selenium Servers
It is not yet clear how to approach this just yet, since the user-data-directory would need to be made available on the same server which holds the browser. In theory, it could work, as long as the Selenium server listens on port 4444 and we can connect to the server via VNC or noVNC to complete the login process.
Contributing
Pull requests are welcome. See the ROADMAP for issues that need research and attention.
For other ideas, please consider first opening an issue to discuss the idea. This increases the likelihood that the work is accepted.
To run from the codebase, clone the project and then install node_modules:
$ npm installRun the tests:
$ npm testTo run the application:
$ npm startLicense
Copyright (c) James Mortensen, 2022 MIT License