
ah-elasticsearch-orm
v0.4.2
Published
An Elasticsearch ORM for ActionHero Projects. Provides CRUD instance methods, finders, updates, and collection abstractions
Downloads
24
Maintainers
 evantahler
evantahlerReadme
ah-elasticsearch-orm
An Elasticsearch ORM for ActionHero


Versions Supported
| Software | Version | |---------------|-----------| | ActionHero | >=14.0.0 | | Node.JS | >=4.0.0 | | ElasticSearch | >=2.0.0 |
Migrations and Defintions.
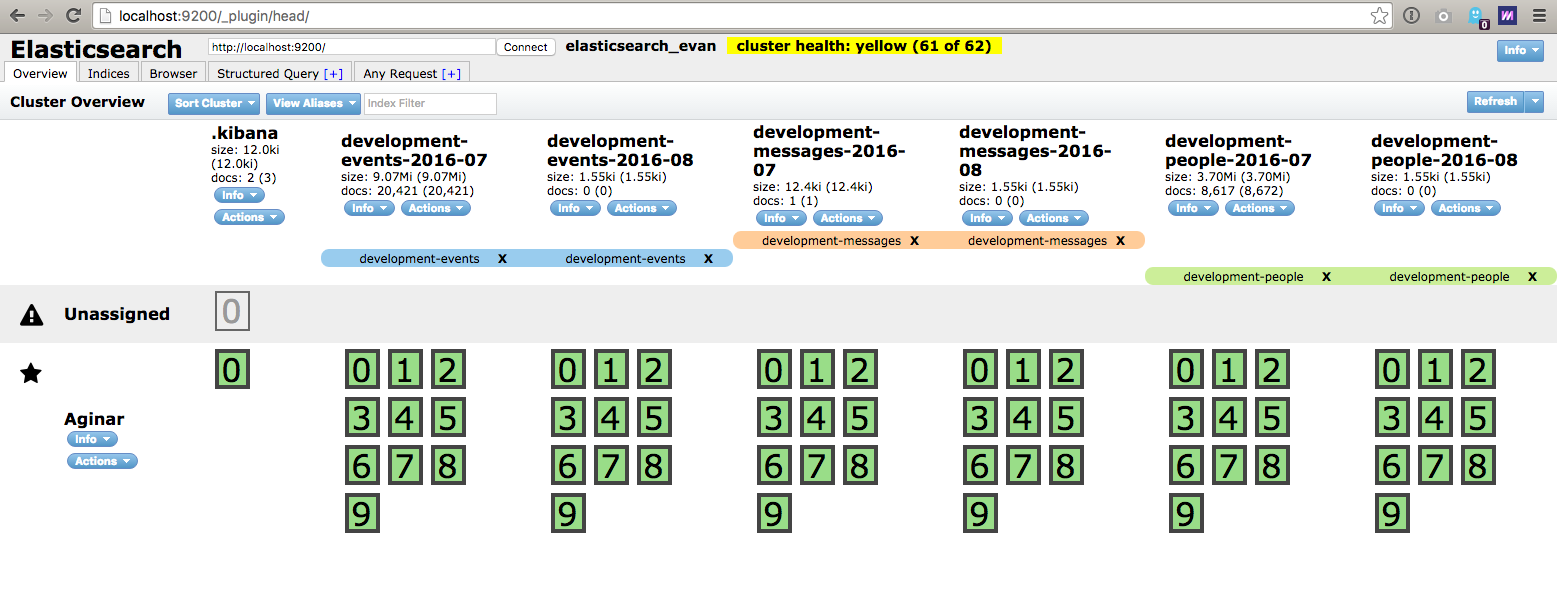
This tool will run migrations creating a new index for every month based on your definitions. We will also apply an alias to each index in the group. This allows you to easily scale your indexes, and have fine-grained control over deleting old data. You define where your index definitions are located in your project via api.config.elasticsearch.indexDefinitions.
For example, if you wanted to create a "people" index for your project, you might have:
// from ./db/elasticsearch/indexes/people.json
module.exports = {
"settings": {
"number_of_shards": parseInt(process.env.NUMBER_OF_SHARDS || 10),
"number_of_replicas": parseInt(process.env.NUMBER_OF_REPLICAS || 0),
"index":{
"analysis":{
"analyzer":{
"analyzer_keyword":{
"tokenizer":"keyword",
"filter":"lowercase"
}
}
}
}
},
"mappings": {
"person": {
"dynamic_templates": [
{
"strings": {
"match_mapping_type": "string",
"mapping": {
"type": "string",
"analyzer":"analyzer_keyword",
}
}
}
],
"properties": {
// *** THESE ARE ALWAYS REQUIRED ***
"guid": { "type": "keyword", "required": true },
"createdAt": { "type": "date", "required": true },
"updatedAt": { "type": "date", "required": true },
"data": { "type": "object", "required": true },
"source": { "type": "keyword", "required": true },
"email": { "type": "string", "required": true },
"location": {
"type": "geo_point",
"geohash_precision": (process.env.GEOHASH_PRECISION || "1km"),
"required": false
},
}
}
},
"warmers" : {},
"aliases" : {"people": {}}
};Note the use of environment variables: GEOHASH_PRECISION, NUMBER_OF_SHARDS and NUMBER_OF_SHARDS. This allows you to have a simple index when developing/staging, but have a more complex deployment in production. You can also define custom analyzers, etc.
The name of your index will be sourced from the file. In the example above, the index created would be of the form development-people-2016-07 (api.env + '-' + name + '-' + thisMonth).
This tool allows you define if a property is required or not (boolean). This data will not be sent to the ElasticSearch index, but will be used for instance validation. Note that to use this tool properly, the follow properties are required for every model:
"guid": { "type": "string", "required": true },"createdAt": { "type": "date", "required": true },"updatedAt": { "type": "date", "required": true },"data": { "type": "object", "required": true },
The default if you don't define required on a property is true.
It is safe to run the migration more than once, as indexes which already exist will be skipped.
> npm run migrate
> [email protected] migrate:elasticsearch /Users/evan/PROJECTS/my-app
> ah-elasticsearch-orm migrate
-> index: development-people-2016-07 already exists
-> creating index: development-people-2016-08From within your project, you can run ./node_modules/.bin/ah-elasticsearch-orm migrate to run migration. You can also make a short hand for this in your scripts section of your package.json, ie:
"scripts": {
"help": "actionhero help",
"start": "actionhero start",
"actionhero": "actionhero",
"startCluster": "actionhero startCluster",
"console": "actionhero console",
"migrate": "ah-elasticsearch-orm migrate",
"test": "NODE_ENV=test npm run migrate && NODE_ENV=test mocha",
}Instances
Instances take the form:
{
"guid": "abc123",
"createdAt": "123",
"updatedAt": "456",
"data":{
"firstName": "Evan",
"lastName": "Tahler",
}
}Top level properties end up defined at the top level of the ElasticSearch instance's _source. Anything else can be added to _source.data. This allows some parts of your schema to be flexible and other parts to have a rigid type and schema. Top level properties are required when creating a new instance.
Ensure that uniqueFields are also required by your mapping by defining the field at the top level. Top level properties of your index will be required for all models.
Warning!
Elasticsearch is a search tool; and is eventually consistent. It is great for storing massive amounts of data, but some of the normal database semantics (like unique primary keys) which you might expect are not available. This tool attempts to do some data integrity checks, but rapid creation of instances with similar keys will result in conflicting data. We rely on EalsticSearch's search tools to check if a GUID is already in use, but it takes time for new objects to become availalbe to the search. More data can be found here and here.
Create
Persists an instance to the database.
Notes:
- You do not need to provide a
guid. If you don't one will be generated for you. Generated guids look like:84da25219b3e47e793f1cab262088d22, and are generated viauuid.v4()(and then stripped of spaces). - If you provide a guid that already exists in the database, the command will fail.
- If you provide data which would conflict with
api.config.elasticsearch.uniqueFields[type], the command will fail.
Example create action:
exports.personCreate = {
name: 'person:create',
description: 'person:create',
outputExample: {},
middleware: [],
inputs: {
guid: { required: false },
data: { required: true },
source: { required: true },
createdAt: {
required: false,
formatter: function(p){
return new Date(parseInt(p));
}
},
},
run: function(api, data, next){
var person = new api.models.Person();
if(data.params.guid){ person.data.guid = data.params.guid; }
if(data.params.source){ person.data.source = data.params.source; }
if(data.params.createdAt){ person.data.createdAt = data.params.createdAt; }
for(var i in data.params.data){
if(person.data[i] === null || person.data[i] === undefined){
person.data[i] = data.params.data[i];
}
}
person.create(function(error){
if(!error){ data.response.guid = person.data.guid; }
return next(error);
});
}
};Edit
Edit an existing instance which is saved to ElasticSearch.
Notes:
- If you provide data which would conflict with
api.config.elasticsearch.uniqueFields[type], the command will fail. - To delete a property in the
datahash, you can use the key_delete/ See the "special keys" section for more information.
Example edit action:
exports.personEdit = {
name: 'person:edit',
description: 'person:edit',
outputExample: {},
middleware: [],
inputs: {
guid: { required: true },
source: { required: false },
data: { required: true },
},
run: function(api, data, next){
var person = new api.models.Person(data.params.guid);
if(data.params.source){ person.data.source = data.params.source; }
for(var i in data.params.data){ person.data[i] = data.params.data[i]; }
person.edit(function(error){
if(error){ return next(error); }
data.response.person = person.data;
return next();
});
}
};Hydrate
Load up data from ElasticSearch about an instance (view).
Example view action:
exports.personView = {
name: 'person:view',
description: 'person:view',
outputExample: {},
middleware: [],
inputs: {
guid: { required: true },
},
run: function(api, data, next){
var person = new api.models.Person(data.params.guid);
person.hydrate(function(error){
if(error){ return next(error); }
data.response.person = person.data;
return next();
});
}
};Del
Delete an instance from the database.
Example del action:
exports.personDelete = {
name: 'person:delete',
description: 'person:delete',
outputExample: {},
middleware: [],
inputs: {
guid: { required: true },
},
run: function(api, data, next){
var person = new api.models.Person(data.params.guid);
// load the instance to be sure it exists
person.hydrate(function(error){
if(error){ return next(error); }
person.del(next);
});
}
};
Aggregations
Aggregation
Return counts of instances based on keys you specify, over a date range.
api.elasticsearch.aggregation(alias, searchKeys, searchValues, start, end, dateField, agg, aggField, interval, cacheTime, callback)
alias: The Alias (or specific index) you want to search insearchKeys: An array of keys you expect to search over.searchValues: An array of the values you want to exist for searchKeys.start: A Date object indicating the start range of dateField to search for.end: A Date object indicating the end range of dateField to search for.dateField: The name of the top-level date key to search over.agg: The name of the aggregation (From the ElasticSearch API)aggField: The name of the field to group over.interval: The resolution of the resulting buckets. See the "Notes" section for allowed intervals.cacheTimeHow long to cache the results of this query for (ms) (optional)callback: callback takes the form of(error, data, fromCache)
An example to ask: "How many people whose names start with the letter "E" were created in the last month? Show me the answer in an hour resolution."
api.elasticsearch.aggregation(
'people',
['guid', 'data.firstName'],
['_exists', 'e*'],
( new Date().setDate(today.getDate()-30) ),
( new Date() ),
'createdAt',
'date_histogram',
'createdAt',
'hour',
callback
);Distinct
Count up the unique instances grouped by the key you specify
api.elasticsearch.distinct(alias, searchKeys, searchValues, start, end, dateField, field, cacheTime, callback)
alias: The Alias (or specific index) you want to search insearchKeys: An array of keys you expect to search over.searchValues: An array of the values you want to exist for searchKeys.start: A Date object indicating the start range of dateField to search for.end: A Date object indicating the end range of dateField to search for.dateField: The name of the top-level date key to search over.field: The field that we want to count unique instances of.cacheTimeHow long to cache the results of this query for (ms) (optional)callback: callback takes the form of(error, data, fromCache)
An example to ask: "How many people whose names start with the letter "E" were created in the last month? Show me how many unique firstNames there are."
api.elasticsearch.distinct(
'people',
['guid', 'data.firstName'],
['_exists', 'e*'],
( new Date().setDate(today.getDate()-30) ),
( new Date() ),
'createdAt',
'data.firstName',
callback
);Mget
Return the hydrated results from an array of guids.
api.elasticsearch.mget(alias, ids, cacheTime, callback)
alias: The Alias (or specific index) you want to search inids: An array of GUIDscacheTimeHow long to cache the results of this query for (ms) (optional)callback: callback takes the form of(error, data, fromCache)
An example to ask: "Hydrate these person's guids: aaa, bbb, ccc"
api.elasticsearch.mget(
'people',
['aaa', 'bbb', 'ccc'],
callback
);Count
Return the number of instances in the index/alias, optionally filtered by a query.
api.elasticsearch.count(alias, searchKeys, searchValues, cacheTime, callback)
alias: The Alias (or specific index) you want to search insearchKeys: An array of keys you expect to search over (can be null).searchValues: An array of the values you want to exist for searchKeys (can be null).cacheTimeHow long to cache the results of this query for (ms) (optional)callback: callback takes the form of(error, count, fromCache)
An example to ask: "How many people are there with an E first name?"
api.elasticsearch.mget(
'people',
['data.firstName'],
['e*'],
callback
);Scroll
Load all results (regardless of pagination) which match a specific ElasticSearch query. Note: This aggregation is never cached.
api.elasticsearch.scroll(alias, query, fields, cacheTime, callback)
alias: The Alias (or specific index) you want to search inquery: The ElasticSearch query to return the results offields: The fields to return (or*)callback: callback takes the form of(error, data)
An example to ask: "How many people have the firstName Evan? Get me all of their email addresses."
api.elasticsearch.scroll(
'people',
{"bool": {"must": [{"term": {"data.firstName": "evan"}}]}}
['data.email'],
callback
);Search
Preform a paginated ElasticSearch query, returning the total results and the requested ordered and paginated segment.
api.elasticsearch.search(alias, searchKeys, searchValues, from, size, sort, cacheTime, callback)
alias: The Alias (or specific index) you want to search insearchKeys: An array of keys you expect to search over.searchValues: An array of the values you want to exist for searchKeys.from: The starting ID of the result set (offset).size: The number of results to return (limit).sort: How to order the result set (From the ElasticSearch API).cacheTimeHow long to cache the results of this query for (ms) (optional)callback: callback takes the form of(error, data, totalResults, fromCache)
An example to ask: "Show me instances #50-#100 of people whose first names start with the letter E. Sort them by createdAt"
api.elasticsearch.search(
'people',
['guid', 'data.firstName'],
['_exists', 'e*'],
50,
50,
{ "createdAt" : {"order" : "asc"}}
1000,
callback
);Cache
As you can see above, most of the aggregations (except for scroll) have an optional cacheTime argument (ms). This allows you to cache the results of popular or time-consuming ElasticSearch queries in redis. If you do not pass this value in explicitly, the default as defined by api.config.elasticsearch.cacheTime will be used. Set this to 0 to not use the cache at all.
Rate Limiting
This tool will rate limit how many pending requests to ElasticSearch you will allow. Think of this like a very simple threadpool. The maximum number of requests is defend at api.config.elasticsearch.maxPendingOperations. Once that limit is hit, you have 2 options, defined by api.config.elasticsearch.maxPendingOperationsBehavior.
If you choose 'fail', then an exception will be returned.
If you choose 'delay', then the request will be retried after a time defined by api.config.elasticsearch.maxPendingOperationsSleep (ms).
Special Keys:
- On an instance, setting a key to
_deletewill remove it, IE:person.data.email = '_delete'; person.edit(); - On a search or aggregation, setting a searchKey to
_existswill will search for simply the presence of that key (searchKeysandsearchValues). - On a search or aggregation, setting a searchKey to
_missingwill will search for simply the missing status of that key (searchKeysandsearchValues). - On a search or aggregation, setting a searchKey to a string which contains
"*"will trigger a wildcard search rather than a term search.
Notes:
api.modelsis where constructors for instances live, ie:new api.models.Person()guidis a unique primary key for all instances, and it is set to_idfor the ElasticSearch instance.- By default, all instances will have a
createdAtandupdatedAtproperty at the top of the _source. - When searching, always use lower-case letters. See the example analyzer for a hint at performing normal string searches.
- For aggregations, the interval/format map is:
var format = 'yyyy-MM-dd';
if(interval === 'year'){ format = 'yyyy'; }
else if(interval === 'month'){ format = 'yyyy-MM'; }
else if(interval === 'week'){ format = 'yyyy-MM-dd'; }
else if(interval === 'day'){ format = 'yyyy-MM-dd'; }
else if(interval === 'hour'){ format = 'yyyy-MM-dd HH:00'; }
else if(interval === 'minute'){ format = 'yyyy-MM-dd HH:mm'; }
else if(interval === 'second'){ format = 'yyyy-MM-dd HH:mm:ss'; }