
@sentio/join-monster
v3.3.4
Published
A GraphQL to SQL query execution layer for batch data fetching.
Downloads
21






Readme

![]()

Query Planning and Batch Data Fetching between GraphQL and SQL.
- Read the Documentation: latest, v2, v1 or v0
- Try Demo: basic version or paginated version
- Example Repo
- Supported SQL Dialects (DB Vendors)
What is Join Monster?
Efficient query planning and data fetching for SQL.
Use JOINs and/or batched requests to retrieve all your data.
It takes a GraphQL query and your schema and automatically generates the SQL.
Send that SQL to your database and get back all the data needed to resolve with only one or a few round-trips to the database.
Translate a GraphQL query like this:
{
user(id: 2) {
fullName
email
posts {
id
body
comments {
body
author { fullName }
}
}
}
}...into a couple SQL queries like this:
SELECT
"user"."id" AS "id",
"user"."email_address" AS "email_address",
"posts"."id" AS "posts__id",
"posts"."body" AS "posts__body",
"user"."first_name" AS "first_name",
"user"."last_name" AS "last_name"
FROM accounts AS "user"
LEFT JOIN posts AS "posts" ON "user".id = "posts".author_id
WHERE "user".id = 2
-- then get the right comments for each post
SELECT
"comments"."id" AS "id",
"comments"."body" AS "body",
"author"."id" AS "author__id",
"author"."first_name" AS "author__first_name",
"author"."last_name" AS "author__last_name",
"comments"."post_id" AS "post_id"
FROM comments AS "comments"
LEFT JOIN accounts AS "author" ON "comments".author_id = "author".id
WHERE "comments".archived = FALSE AND "comments"."post_id" IN (2,8,11,12) -- the post IDs from the previous query ...and get back correctly hydrated data.
{
"user": {
"fullName": "Yasmine Rolfson",
"email": "[email protected]",
"posts": [
{
"id": 2,
"body": "Harum unde maiores est quasi totam consequuntur. Necessitatibus doloribus ut totam dolore omnis quos error eos. Rem nostrum assumenda eius veniam fugit dicta in consequuntur. Ut porro dolorem aliquid qui magnam a.",
"comments": [
{
"body": "The AI driver is down, program the multi-byte sensor so we can parse the SAS bandwidth!",
"author": { "fullName": "Yasmine Rolfson" }
},
{
"body": "Try to program the SMS transmitter, maybe it will synthesize the optical firewall!",
"author": { "fullName": "Ole Barrows" }
},
]
},
// other posts omitted for clarity...
]
}
}It works on top of Facebook's graphql-js reference implementation.
All you have to do is add a few properties to the objects in your schema and call the joinMonster function.
A SQL query is "compiled" for you to send to the DBMS.
The data-fetching is efficiently batched.
The data is then hydrated into the right shape for your GraphQL schema.
Why?
More details on the "round-trip" (a.k.a. N+1) problem are here.
- [X] Batching - Fetch all the data in a single, or a few, database query(s).
- [X] Efficient - No over-fetching data. Retrieve only the data that the client actually requested.
- [X] Maintainability - SQL is automatically generated and adaptive. No need to manually write queries or update them when the schema changes.
- [X] Declarative - Simply define the data requirements of the GraphQL fields on the SQL columns.
- [X] Unobtrusive - Coexists with your custom resolve functions and existing schemas. Use it on the whole graph or only in parts. Retain the power and expressiveness in defining your schema.
- [X] Object-relational impedance mismatch - Don't bother duplicating a bunch of object definitions in an ORM. Let GraphQL do your object mapping for you.
Since it works with the reference implementation, the API is all very familiar. Join Monster is a tool built on top to add batch data fetching. You add some special properties along-side the schema definition that Join Monster knows to look for. The use of graphql-js does not change. You still define your types the same way. You can write resolve functions to manipulate the data from Join Monster, or incorporate data from elsewhere without breaking out of your "join-monsterized" schema.
Get Pagination out of the Box
Join Monster has support for several different implementations of pagination, all based on the interface in the Relay Connection Specification. Using Relay on the client is totally optional!
Works with the RelayJS
Great helpers for the Node Interface and automatic pagination for Connection Types. See docs.
Usage with GraphQL
$ npm install join-monster- Take your
GraphQLObjectTypefrom graphql-js and add the SQL table name. - Do the fields need values from some SQL columns? Computed columns? Add some additional properties like
sqlColumn,sqlDeps, orsqlExprto the fields. Join Monster will look at these when analyzing the query. - Got some relations? Write a function that tells Join Monster how to
JOINyour tables and it will hydrate hierarchies of data. - Resolve any type (and all its descendants) by calling
joinMonsterin its resolver. All it needs is theresolveInfoand a callback to send the (one) SQL query to the database. Voila! All your data is returned to the resolver.
import joinMonster from 'join-monster'
import {
GraphQLObjectType,
GraphQLList,
GraphQLString,
GraphQLInt
// and some other stuff
} from 'graphql'
const User = new GraphQLObjectType({
name: 'User',
sqlTable: 'accounts', // the SQL table for this object type is called "accounts"
uniqueKey: 'id', // the id in each row is unique for this table
fields: () => ({
id: {
// the column name is assumed to be the same as the field name
type: GraphQLInt
},
email: {
type: GraphQLString,
// if the column name is different, it must be specified specified
sqlColumn: 'email_address'
},
idEncoded: {
description: 'The ID base-64 encoded',
type: GraphQLString,
// this field uses a sqlColumn and applies a resolver function on the value
// if a resolver is present, the `sqlColumn` MUST be specified even if it is the same name as the field
sqlColumn: 'id',
resolve: user => toBase64(user.idEncoded)
},
fullName: {
description: "A user's first and last name",
type: GraphQLString,
// perhaps there is no 1-to-1 mapping of field to column
// this field depends on multiple columns
sqlDeps: [ 'first_name', 'last_name' ],
// compute the value with a resolver
resolve: user => `${user.first_name} ${user.last_name}`
},
capitalizedLastName: {
type: GraphQLString,
// do a computed column in SQL with raw expression
sqlExpr: (table, args) => `UPPER(${table}.last_name)`
},
// got tables inside tables??
// get it with a JOIN!
posts: {
description: "A List of posts this user has written.",
type: new GraphQLList(Post),
// a function to generate the join condition from the table aliases
sqlJoin(userTable, postTable) {
return `${userTable}.id = ${postTable}.author_id`
}
},
// got a relationship but don't want to add another JOIN?
// get this in a second batch request
comments: {
description: "The comment they have written",
type: new GraphQLList(Comment),
// specify which columns to match up the values
sqlBatch: {
thisKey: 'author_id',
parentKey: 'id'
}
},
// many-to-many relations are supported too
following: {
description: "Other users that this user is following.",
type: new GraphQLList(User),
// name the table that holds the two foreign keys
junction: {
sqlTable: 'relationships',
sqlJoins: [
// first the parent table to the junction
(followerTable, junctionTable, args) => `${followerTable}.id = ${junctionTable}.follower_id`,
// then the junction to the child
(junctionTable, followeeTable, args) => `${junctionTable}.followee_id = ${followeeTable}.id`
]
}
},
numLegs: {
description: 'Number of legs this user has.',
type: GraphQLInt,
// data isn't coming from the SQL table? no problem! joinMonster will ignore this field
resolve: () => 2
}
})
})
const Comment = new GraphQLObjectType({
name: 'Comment',
sqlTable: 'comments',
uniqueKey: 'id',
fields: () => ({
// id and body column names are the same
id: {
type: GraphQLInt
},
body: {
type: GraphQLString
}
})
})
const Post = new GraphQLObjectType({
name: 'Post',
sqlTable: 'posts',
uniqueKey: 'id',
fields: () => ({
id: {
type: GraphQLInt
},
body: {
type: GraphQLString
}
})
})
export const QueryRoot = new GraphQLObjectType({
name: 'Query',
fields: () => ({
// place this user type in the schema
user: {
type: User,
// let client search for users by `id`
args: {
id: { type: GraphQLInt }
},
// how to write the WHERE condition
where: (usersTable, args, context) => {
if (args.id) return `${usersTable}.id = ${args.id}`
},
resolve: (parent, args, context, resolveInfo) => {
// resolve the user and the comments and any other descendants in a single request and return the data!
// all you need to pass is the `resolveInfo` and a callback for querying the database
return joinMonster(resolveInfo, {}, sql => {
// knex is a query library for SQL databases
return knex.raw(sql)
})
}
}
})
})Detailed instructions for set up are found in the docs.
Using with graphql-tools
The GraphQL schema language doesn't let you add arbitrary properties to the type definitions. If you're using something like the Apollo graphql-tools package to write your code with the schema language, you'll need an adapter. See the join-monster-graphql-tools-adapter if you want to use this with graphql-tools.
Running the Demo
$ git clone https://github.com/stems/join-monster-demo.git
$ cd join-monster-demo
$ npm install
$ npm start
# go to http://localhost:3000/graphql
# if you also want to run the paginated version, create postgres database from the dump provided
psql $YOUR_DATABASE < data/paginated-demo-dump.sql
DATABASE_URL=postgres://$USER:$PASS@$HOST/$YOUR_DATABASE npm start
# go to http://localhost:3000/graphql-relayExplore the schema, try out some queries, and see what the resulting SQL queries and responses look like in our custom version of GraphiQL!
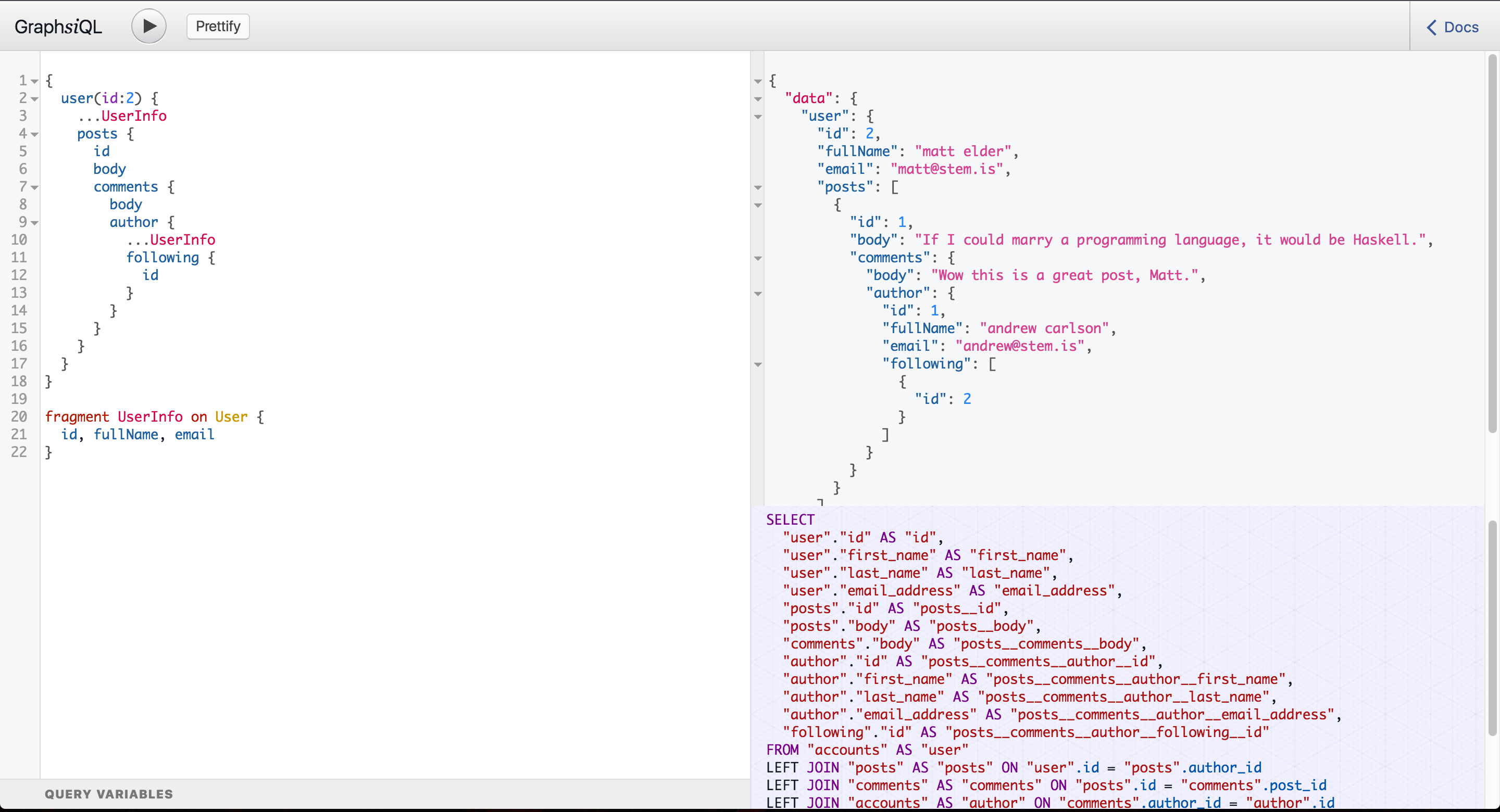
There's still a lot of work to do. Please feel free to fork and submit a Pull Request!
Future Work
- [ ] Address this known bug #126.
- [ ] Support custom
ORDER BYexpressions #138. - [ ] Support binding parameters #169.
- [ ] Write static Flow types.
- [ ] Support "lookup tables" where a column might be an enum code to look up in another table.
- [ ] Support "hyperjunctions" where many-to-many relations can join through multiple junction tables.
- [ ] Cover more SQL dialects, like MSSQL and DB2.