
@huggingface/tasks
v0.13.13
Published
List of ML tasks for huggingface.co/tasks
Downloads
391,385




Readme
Tasks
This package contains the definition files (written in Typescript) for the huggingface.co hub's:
- pipeline types (a.k.a. task types) - used to determine which widget to display on the model page, and which inference API to run.
- default widget inputs - when they aren't provided in the model card.
- definitions and UI elements for model and dataset libraries.
Please add any missing ones to these definitions by opening a PR. Thanks 🔥
⚠️ The hub's definitive doc is at https://huggingface.co/docs/hub.
Definition of Tasks
This package also contains data used to define https://huggingface.co/tasks.
The Task pages are made to lower the barrier of entry to understand a task that can be solved with machine learning and use or train a model to accomplish it. It's a collaborative documentation effort made to help out software developers, social scientists, or anyone with no background in machine learning that is interested in understanding how machine learning models can be used to solve a problem.
The task pages avoid jargon to let everyone understand the documentation, and if specific terminology is needed, it is explained on the most basic level possible. This is important to understand before contributing to Tasks: at the end of every task page, the user is expected to be able to find and pull a model from the Hub and use it on their data and see if it works for their use case to come up with a proof of concept.
How to Contribute
You can open a pull request to contribute a new documentation about a new task. Under src/tasks we have a folder for every task that contains two files, about.md and data.ts. about.md contains the markdown part of the page, use cases, resources and minimal code block to infer a model that belongs to the task. data.ts contains redirections to canonical models and datasets, metrics, the schema of the task and the information the inference widget needs.
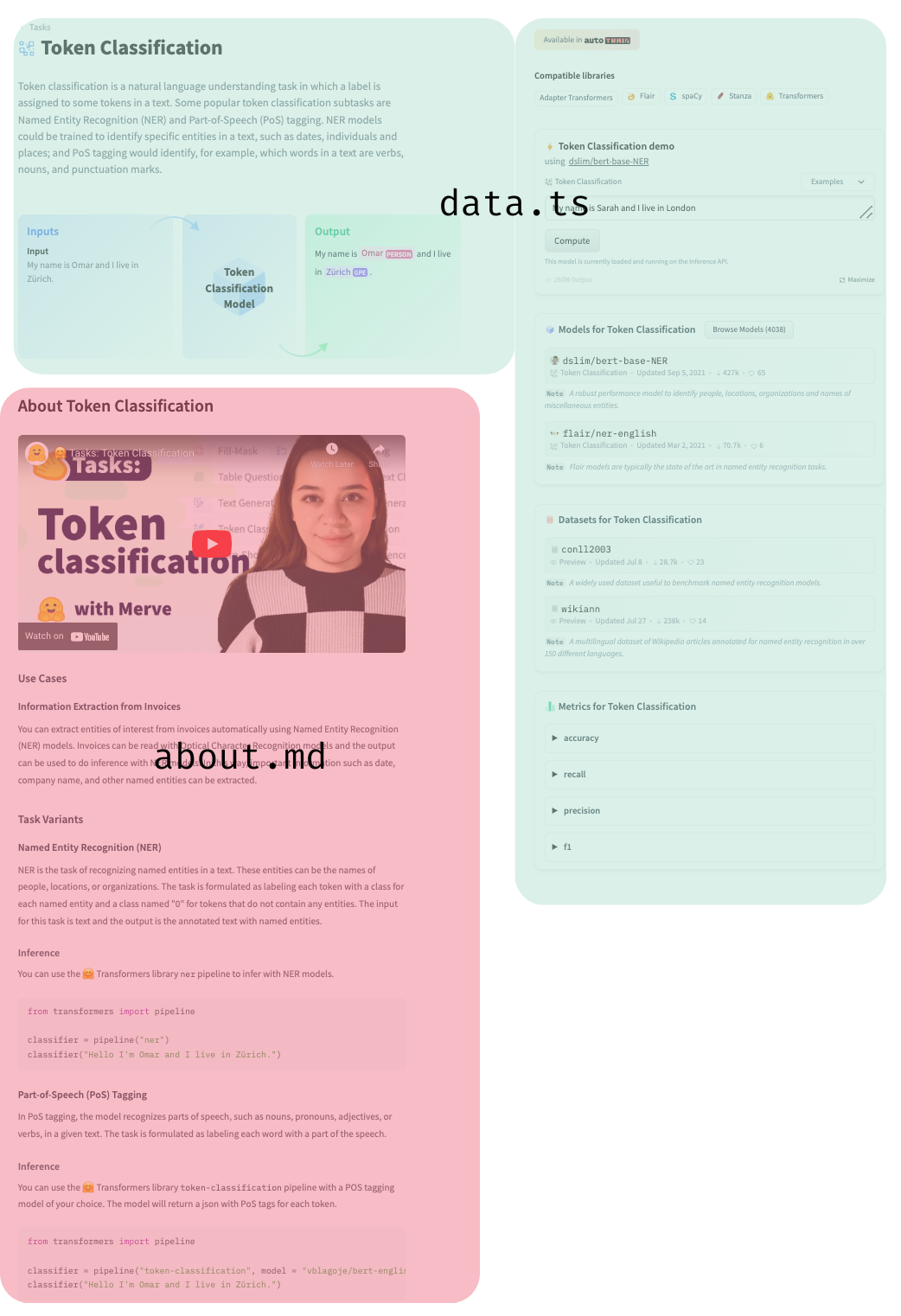
We have a dataset that contains data used in the inference widget. The last file is const.ts, which has the task to library mapping (e.g. spacy to token-classification) where you can add a library. They will look in the top right corner like below.

This might seem overwhelming, but you don't necessarily need to add all of these in one pull request or on your own, you can simply contribute one section. Feel free to ask for help whenever you need.