
@extractus/article-extractor
v8.0.16
Published
To extract main article from given URL
Downloads
18,141


Readme
@extractus/article-extractor
Extract main article, main image and meta data from URL.
![]()
![]()
![]()
(This library is derived from article-parser renamed.)
Demo
Install & Usage
Node.js
npm i @extractus/article-extractor
# pnpm
pnpm i @extractus/article-extractor
# yarn
yarn add @extractus/article-extractor// es6 module
import { extract } from '@extractus/article-extractor'Deno
import { extract } from 'https://esm.sh/@extractus/article-extractor'
// deno > 1.28
import { extract } from 'npm:@extractus/article-extractor'Browser
import { extract } from 'https://esm.sh/@extractus/article-extractor'Please check the examples for reference.
APIs
extract()
Load and extract article data. Return a Promise object.
Syntax
extract(String input)
extract(String input, Object parserOptions)
extract(String input, Object parserOptions, Object fetchOptions)Example:
import { extract } from '@extractus/article-extractor'
const input = 'https://www.cnbc.com/2022/09/21/what-another-major-rate-hike-by-the-federal-reserve-means-to-you.html'
// here we use top-level await, assume current platform supports it
try {
const article = await extract(input)
console.log(article)
} catch (err) {
console.error(err)
}The result - article - can be null or an object with the following structure:
{
url: String,
title: String,
description: String,
image: String,
author: String,
favicon: String,
content: String,
published: Date String,
type: String, // page type
source: String, // original publisher
links: Array, // list of alternative links
ttr: Number, // time to read in second, 0 = unknown
}Parameters
input required
URL string links to the article or HTML content of that web page.
parserOptions optional
Object with all or several of the following properties:
wordsPerMinute: Number, to estimate time to read. Default300.descriptionTruncateLen: Number, max num of chars generated for description. Default210.descriptionLengthThreshold: Number, min num of chars required for description. Default180.contentLengthThreshold: Number, min num of chars required for content. Default200.
For example:
import { extract } from '@extractus/article-extractor'
const article = await extract('https://www.cnbc.com/2022/09/21/what-another-major-rate-hike-by-the-federal-reserve-means-to-you.html', {
descriptionLengthThreshold: 120,
contentLengthThreshold: 500
})
console.log(article)fetchOptions optional
fetchOptions is an object that can have the following properties:
headers: to set request headersproxy: another endpoint to forward the request toagent: a HTTP proxy agentsignal: AbortController signal or AbortSignal timeout to terminate the request
For example, you can use this param to set request headers to fetch as below:
import { extract } from '@extractus/article-extractor'
const url = 'https://www.cnbc.com/2022/09/21/what-another-major-rate-hike-by-the-federal-reserve-means-to-you.html'
const article = await extract(url, {}, {
headers: {
'user-agent': 'Opera/9.60 (Windows NT 6.0; U; en) Presto/2.1.1'
}
})
console.log(article)You can also specify a proxy endpoint to load remote content, instead of fetching directly.
For example:
import { extract } from '@extractus/article-extractor'
const url = 'https://www.cnbc.com/2022/09/21/what-another-major-rate-hike-by-the-federal-reserve-means-to-you.html'
await extract(url, {}, {
headers: {
'user-agent': 'Opera/9.60 (Windows NT 6.0; U; en) Presto/2.1.1'
},
proxy: {
target: 'https://your-secret-proxy.io/loadXml?url=',
headers: {
'Proxy-Authorization': 'Bearer YWxhZGRpbjpvcGVuc2VzYW1l...'
},
}
})Passing requests to proxy is useful while running @extractus/article-extractor on browser. View examples/browser-article-parser as reference example.
For more info about proxy authentication, please refer HTTP authentication
For a deeper customization, you can consider using Proxy to replace fetch behaviors with your own handlers.
Another way to work with proxy is use agent option instead of proxy as below:
import { extract } from '@extractus/article-extractor'
import { HttpsProxyAgent } from 'https-proxy-agent'
const proxy = 'http://abc:[email protected]:31113'
const url = 'https://www.cnbc.com/2022/09/21/what-another-major-rate-hike-by-the-federal-reserve-means-to-you.html'
const article = await extract(url, {}, {
agent: new HttpsProxyAgent(proxy),
})
console.log('Run article-extractor with proxy:', proxy)
console.log(article)For more info about https-proxy-agent, check its repo.
By default, there is no request timeout. You can use the option signal to cancel request at the right time.
The common way is to use AbortControler:
const controller = new AbortController()
// stop after 5 seconds
setTimeout(() => {
controller.abort()
}, 5000)
const data = await extract(url, null, {
signal: controller.signal,
})A newer solution is AbortSignal's timeout() static method:
// stop after 5 seconds
const data = await extract(url, null, {
signal: AbortSignal.timeout(5000),
})For more info:
extractFromHtml()
Extract article data from HTML string. Return a Promise object as same as extract() method above.
Syntax
extractFromHtml(String html)
extractFromHtml(String html, String url)
extractFromHtml(String html, String url, Object parserOptions)Example:
import { extractFromHtml } from '@extractus/article-extractor'
const url = 'https://www.cnbc.com/2022/09/21/what-another-major-rate-hike-by-the-federal-reserve-means-to-you.html'
const res = await fetch(url)
const html = await res.text()
// you can do whatever with this raw html here: clean up, remove ads banner, etc
// just ensure a html string returned
const article = await extractFromHtml(html, url)
console.log(article)Parameters
html required
HTML string which contains the article you want to extract.
url optional
URL string that indicates the source of that HTML content.
article-extractor may use this info to handle internal/relative links.
parserOptions optional
See parserOptions above.
Transformations
Sometimes the default extraction algorithm may not work well. That is the time when we need transformations.
By adding some functions before and after the main extraction step, we aim to come up with a better result as much as possible.
There are 2 methods to play with transformations:
addTransformations(Object transformation | Array transformations)removeTransformations(Array patterns)
At first, let's talk about transformation object.
transformation object
In @extractus/article-extractor, transformation is an object with the following properties:
patterns: required, a list of regexps to match the URLspre: optional, a function to process raw HTMLpost: optional, a function to process extracted article
Basically, the meaning of transformation can be interpreted like this:
with the urls which match these
patternslet's runprefunction to normalize HTML content then extract main article content with normalized HTML, and if success let's runpostfunction to normalize extracted article content
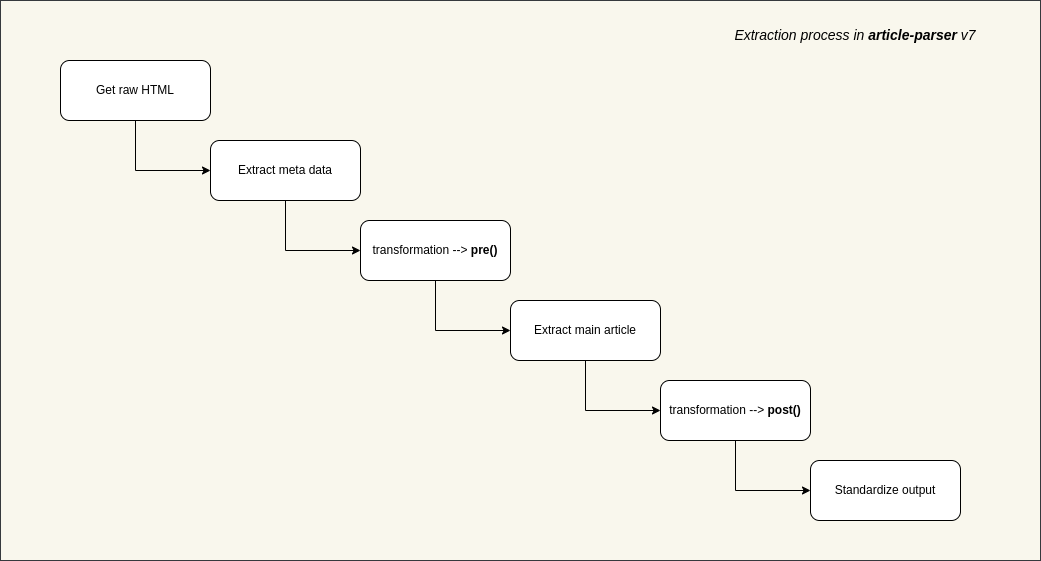
Here is an example transformation:
{
patterns: [
/([\w]+.)?domain.tld\/*/,
/domain.tld\/articles\/*/
],
pre: (document) => {
// remove all .advertise-area and its siblings from raw HTML content
document.querySelectorAll('.advertise-area').forEach((element) => {
if (element.nodeName === 'DIV') {
while (element.nextSibling) {
element.parentNode.removeChild(element.nextSibling)
}
element.parentNode.removeChild(element)
}
})
return document
},
post: (document) => {
// with extracted article, replace all h4 tags with h2
document.querySelectorAll('h4').forEach((element) => {
const h2Element = document.createElement('h2')
h2Element.innerHTML = element.innerHTML
element.parentNode.replaceChild(h2Element, element)
})
// change small sized images to original version
document.querySelectorAll('img').forEach((element) => {
const src = element.getAttribute('src')
if (src.includes('domain.tld/pics/150x120/')) {
const fullSrc = src.replace('/pics/150x120/', '/pics/original/')
element.setAttribute('src', fullSrc)
}
})
return document
}
}- To write better transformation logic, please refer linkedom and Document Object.
addTransformations(Object transformation | Array transformations)
Add a single transformation or a list of transformations. For example:
import { addTransformations } from '@extractus/article-extractor'
addTransformations({
patterns: [
/([\w]+.)?abc.tld\/*/
],
pre: (document) => {
// do something with document
return document
},
post: (document) => {
// do something with document
return document
}
})
addTransformations([
{
patterns: [
/([\w]+.)?def.tld\/*/
],
pre: (document) => {
// do something with document
return document
},
post: (document) => {
// do something with document
return document
}
},
{
patterns: [
/([\w]+.)?xyz.tld\/*/
],
pre: (document) => {
// do something with document
return document
},
post: (document) => {
// do something with document
return document
}
}
])The transformations without patterns will be ignored.
removeTransformations(Array patterns)
To remove transformations that match the specific patterns.
For example, we can remove all added transformations above:
import { removeTransformations } from '@extractus/article-extractor'
removeTransformations([
/([\w]+.)?abc.tld\/*/,
/([\w]+.)?def.tld\/*/,
/([\w]+.)?xyz.tld\/*/
])Calling removeTransformations() without parameter will remove all current transformations.
Priority order
While processing an article, more than one transformation can be applied.
Suppose that we have the following transformations:
[
{
patterns: [
/http(s?):\/\/google.com\/*/,
/http(s?):\/\/goo.gl\/*/
],
pre: function_one,
post: function_two
},
{
patterns: [
/http(s?):\/\/goo.gl\/*/,
/http(s?):\/\/google.inc\/*/
],
pre: function_three,
post: function_four
}
]As you can see, an article from goo.gl certainly matches both them.
In this scenario, @extractus/article-extractor will execute both transformations, one by one:
function_one -> function_three -> extraction -> function_two -> function_four
sanitize-html's options
@extractus/article-extractor uses sanitize-html to make a clean sweep of HTML content.
Here is the default options
Depending on the needs of your content system, you might want to gather some HTML tags/attributes, while ignoring others.
There are 2 methods to access and modify these options in @extractus/article-extractor.
getSanitizeHtmlOptions()setSanitizeHtmlOptions(Object sanitizeHtmlOptions)
Read sanitize-html docs for more info.
Test
git clone https://github.com/extractus/article-extractor.git
cd article-extractor
pnpm i
pnpm test
Quick evaluation
git clone https://github.com/extractus/article-extractor.git
cd article-extractor
pnpm i
pnpm eval {URL_TO_PARSE_ARTICLE}License
The MIT License (MIT)
Support the project
If you find value from this open source project, you can support in the following ways:
- Give it a star ⭐
- Buy me a coffee: https://paypal.me/ndaidong 🍵
- Subscribe Article Extractor service on RapidAPI 😉
Thank you.