
@datayoga-io/lineage
v1.0.15
Published
produce lineage documentation for data pipeline
Downloads
38
Maintainers
 zalmane
zalmaneReadme
DataYoga Lineage
This package allows to generate documentation of data pipelines and data lineage charts. It is source agnostic and uses a predefined json/yaml format to represent the dependencies and business logic. The resulting markdown files can be used standalone or as part of a documentation site using tools like MkDocs or VuePress.
Installation
npm install -g @datayoga-io/lineageQuick Start
To quickly get started with Lineage, scaffold a new project. This will create the folder structure along with sample files.
dy-lineage scaffold ./my-projectTo generate the documentation for the new project:
dy-lineage build ./my-project --dest ./docsData Entities
Lineage models the data ecosystem using the following entities:
Datastore - A datastore represents a source or target of data that can hold data at rest or data in motion. Datastores include entities such as a table in a database, a file, or a stream in Kafka. A Datastore can act either as a source or a target of a pipeline.
File - A file is a type of Datastore that represents information stored in files. Files contain metadata about their structure and schema.
Dimension - A dimension table / file is typically used for lookup and constant information that is managed as part of the application code. This often includes lookup values such as country codes.
Runner - A runner is a processing engine capable of running data operations. Every Runner supports one or more programming languages. Some Runners, like a database engine, only support SQL, while others like Spark may support Python, Scala, and Java.
Consumer - A consumer consumes data and presents it to a user. Consumers include reports, dashboards, and interactive applications.
Pipeline - A pipeline represents a series of Jobs that operate on a single Runner.
Job - A job is composed of a series of Steps that fetch information from one or more Datastores, transform them, and store the result in a target Datastore, or perform actions such as sending out alerts or performing HTTP calls.
Job Step - Every step in a job performs a single action. A step can be of a certain type representing the action it performs. A step can be an SQL statement, a Python statement, or a callout to a library. Steps can be chained to create a Directed Acyclic Graph (DAG).
Getting started
Usage
dy-lineage <input folder> -dest <output folder>Lineage will scan the file(s) specified in input and attempt to load information about the catalog. In addition, a folder containing yaml files describing each pipeline's business logic can be provided.
See the Example folder for sample input files and generated output files
Structure of input folder
.
├── .dyrc
├── entities
├── files
├── pipelines
├── datastores
├── relations.dyrc: Used to store global configuration.datastores: Catalog file(s) with information about datastore entities and their metadatafiles: Catalog file(s) with information about file datastore entities and their metadatapipelines: Optional files containing information about the pipelines and business logic flowrelations: Information about the relations between the data entities
Structure of entities files
The entities folder contains the entity definition and metadata for each of the entities.
Each folder can contain one or more files. For convenience, multiple entities can be located in the same yaml file. All *.yaml files are scanned.
Whenever an ID is used, the ID naming convention is: <entity type>:<optional module name>.<entity name>. Module name can be nested: e.g. order_mgmt.weekdays.inbound.load_orders
Pipelines
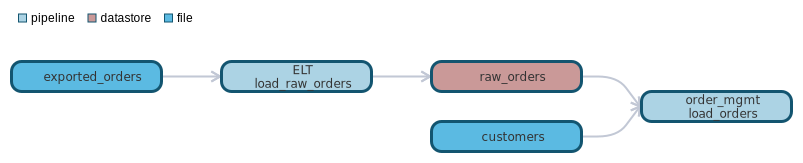
Example:
id: pipeline:order_mgmt.load_orders
title: Load order from SAP
description: |
Loads orders from raw order system. Performs the following calculation on order value:
```order_value = order_qty * order_line_item_value```
classification: PII
metadata:
- triggers: file_arrivalid: unique identifier of this pipeline
title: title to use for document
description: description of the pipeline. Can use markdown format
classification: data classification
metadata: any key,value pairs under the metadata section will be presented as tags in the resulting document
Files
Here is an example of a single yaml holding more than one source definition.
Example:
- id: file:exported_orders
filename: orders_{[0-9]}6.csv
format: delimited
delimiter: ","
header: true
schema:
fields:
- name: order_id
type: int
doc: order number
- name: order_date
type: date
dateformat: MM/dd/YYYY
description: order date
- id: file:customers
filename: customer_full.json
doc: example of a json file with nested schema
format: json
schema:
type: record
fields:
- name: customer_id
type: int
doc: customer identifier
- name: address
type: record
fields:
- name: street
type: string
- name: city
type: string
- name: state
type: string
- name: zip
type: stringDatastore
Example:
- id: datastore:orders
source: table
doc: orders table
schema:
fields:
- name: order_id
type: int
doc: order number
primary_key: True
- name: customer_id
type: double
doc: customer number
primary_key: False
- name: name
type: string
doc: customer nameStructure of relations file
The relations file holds the relationships between the entities.
Example:
- source: datastore:raw_orders
target: pipeline:order_mgmt.load_orders
- source: pipeline:order_mgmt.load_orders
target: datastore:orders